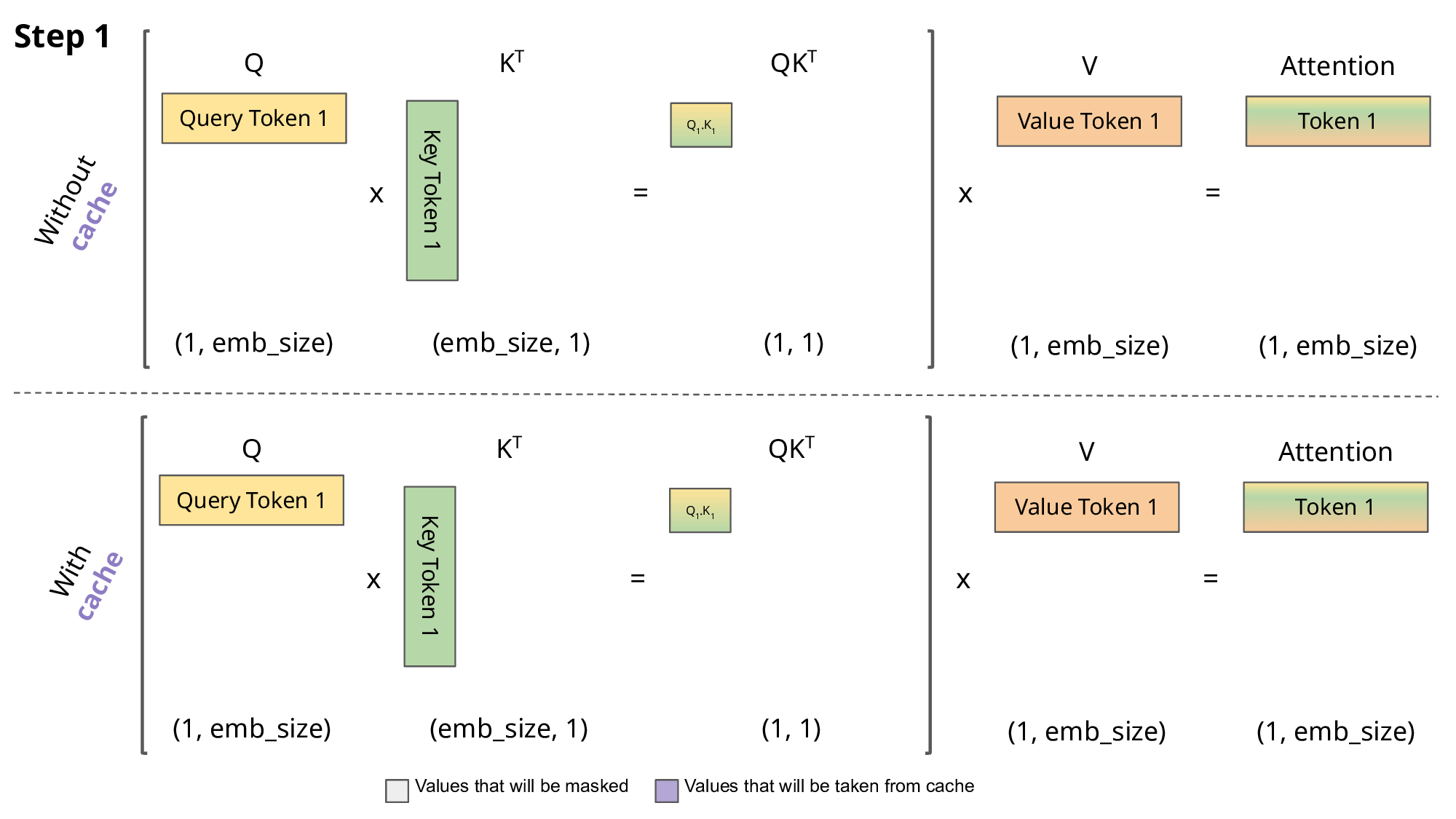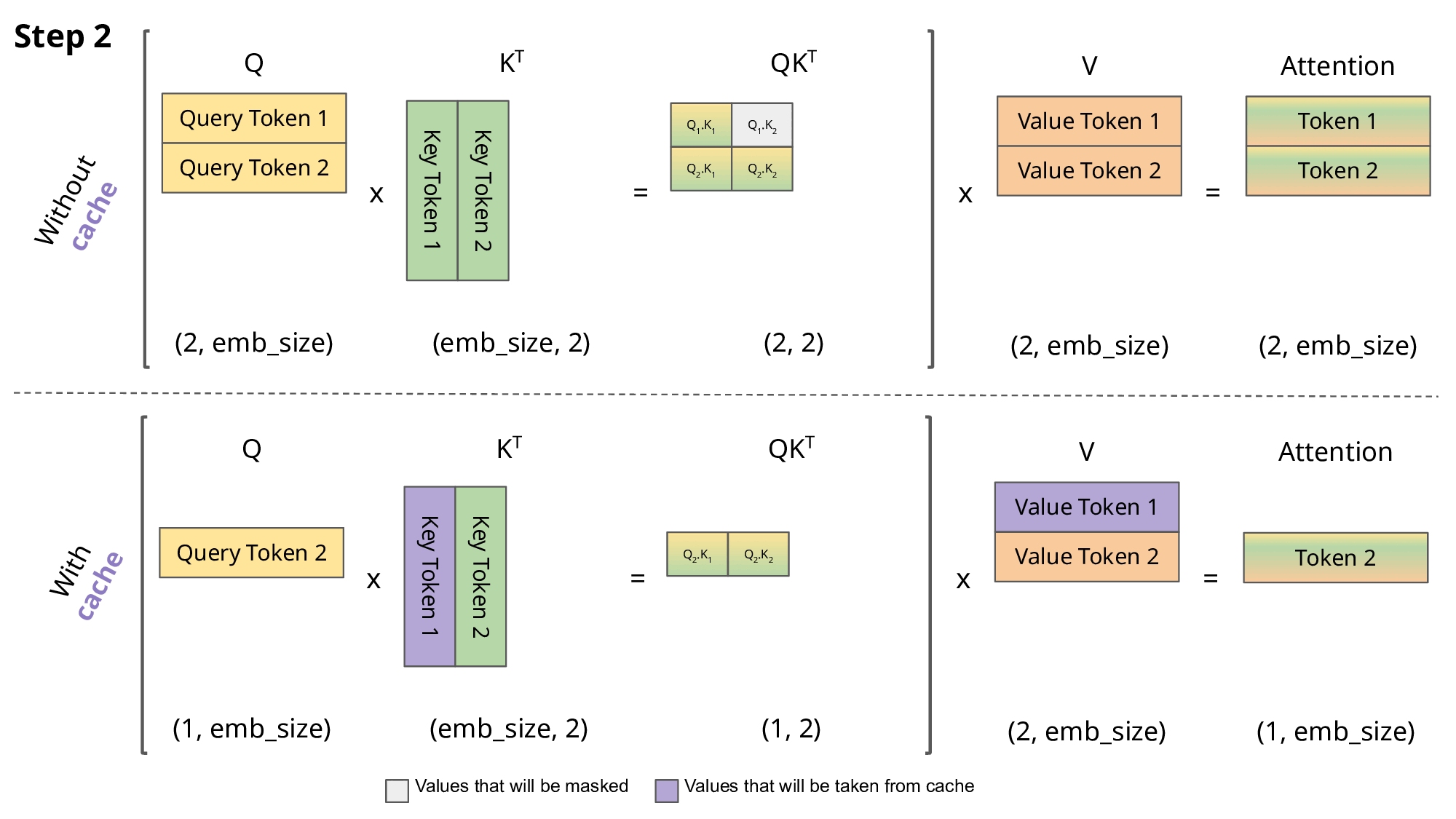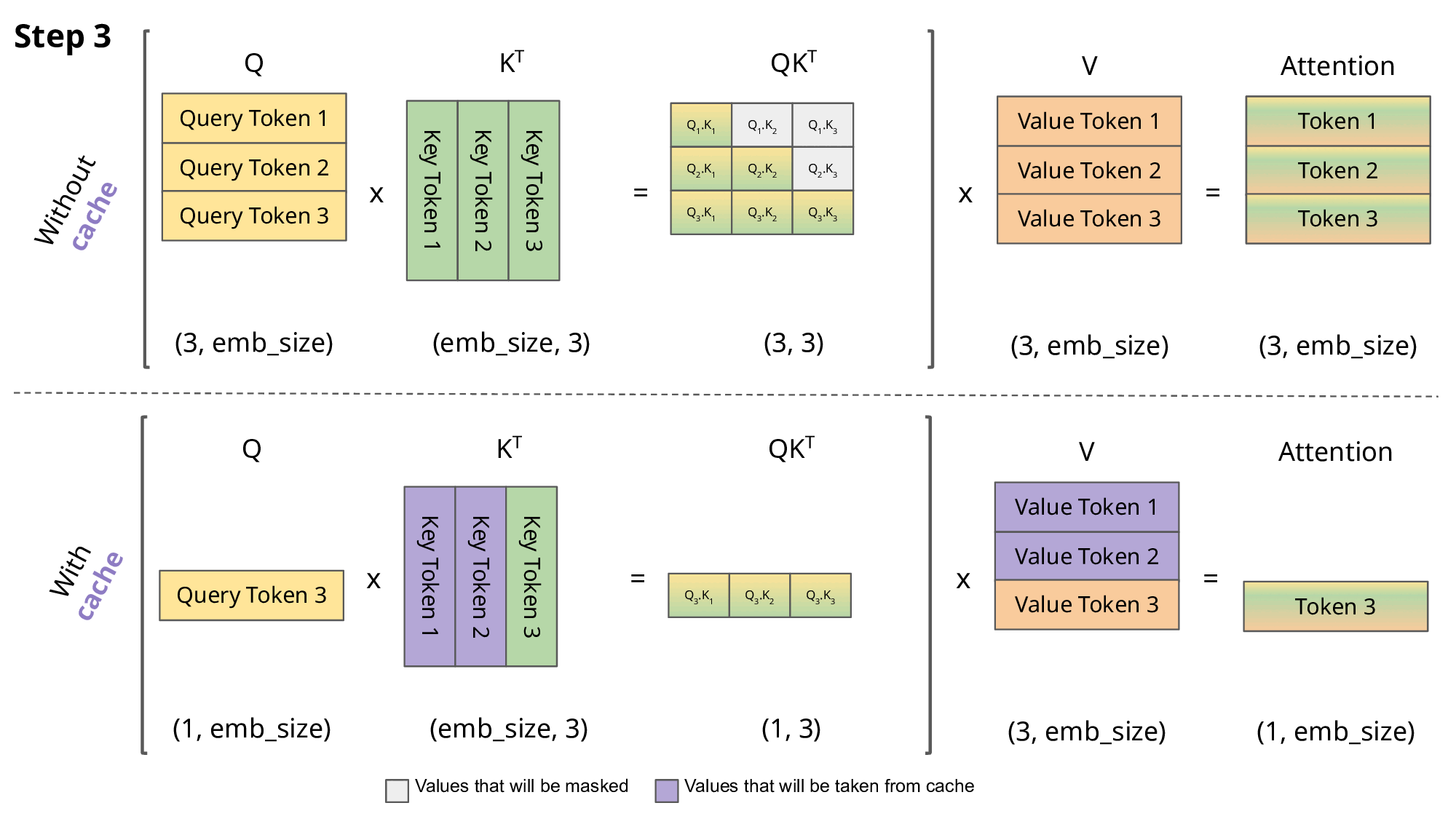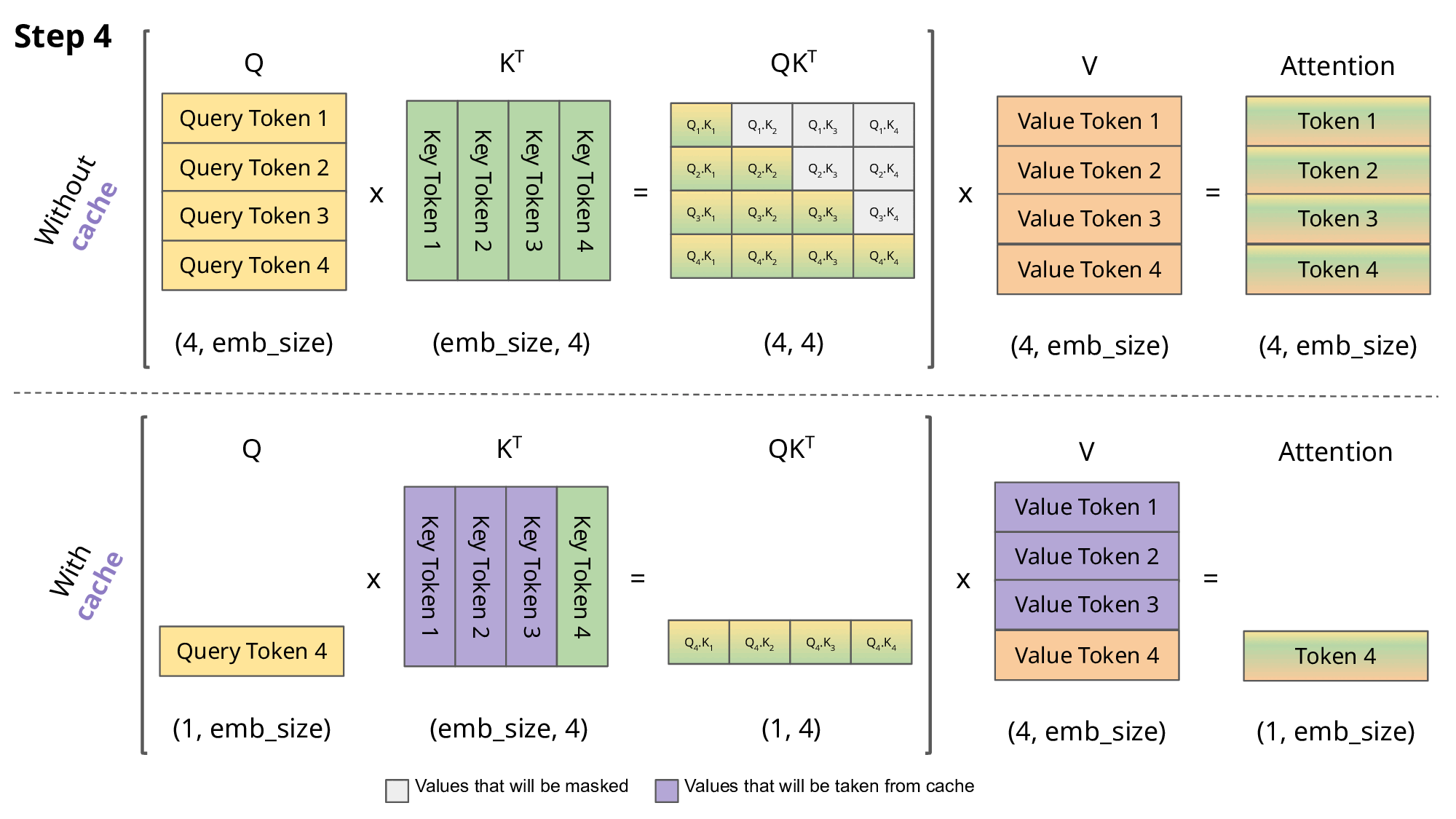
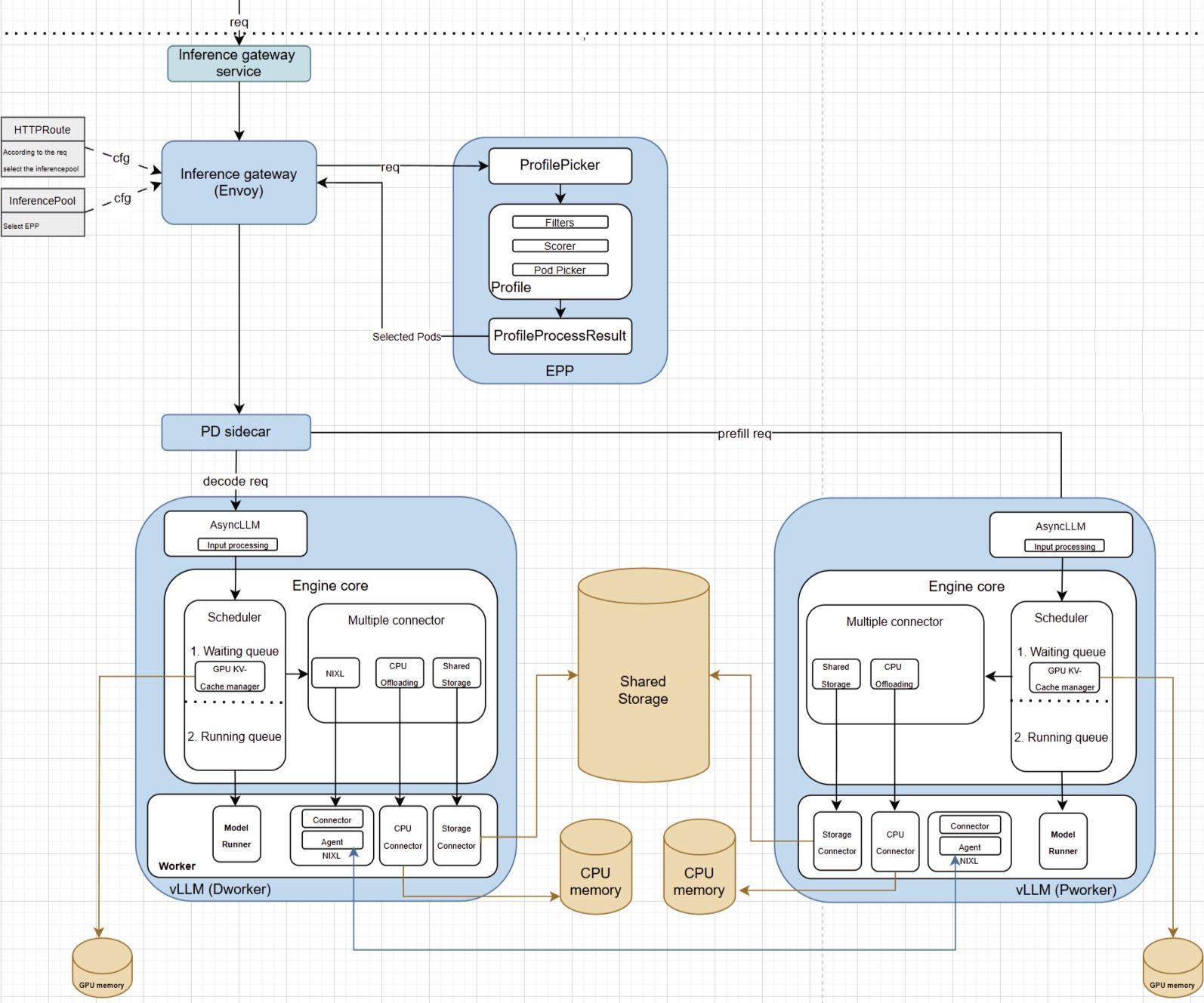
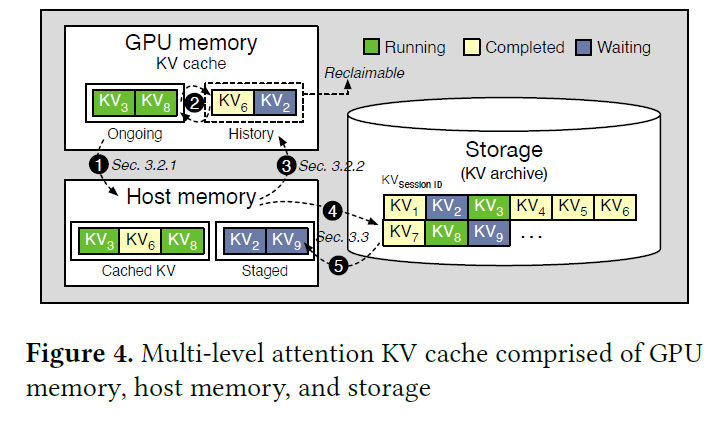
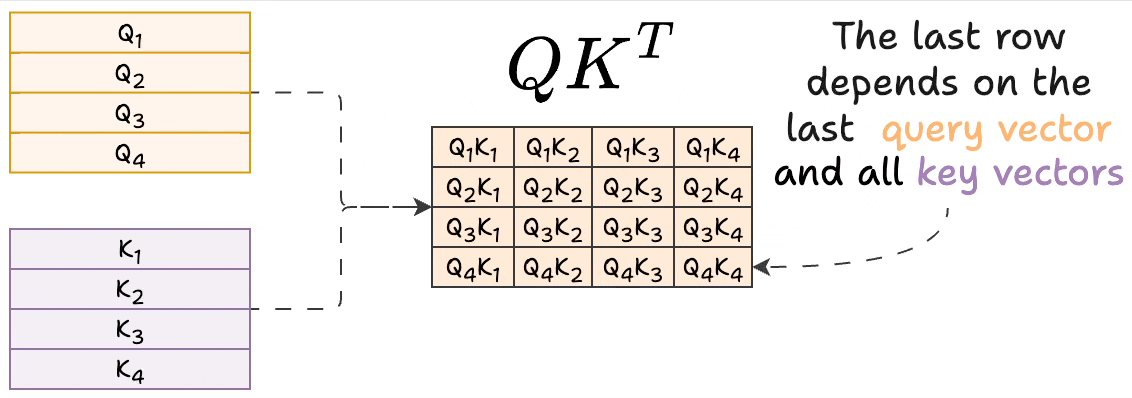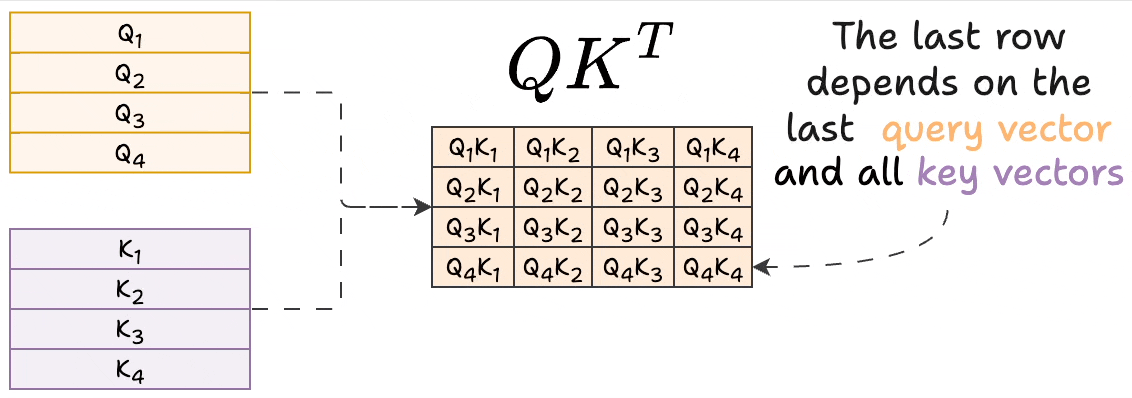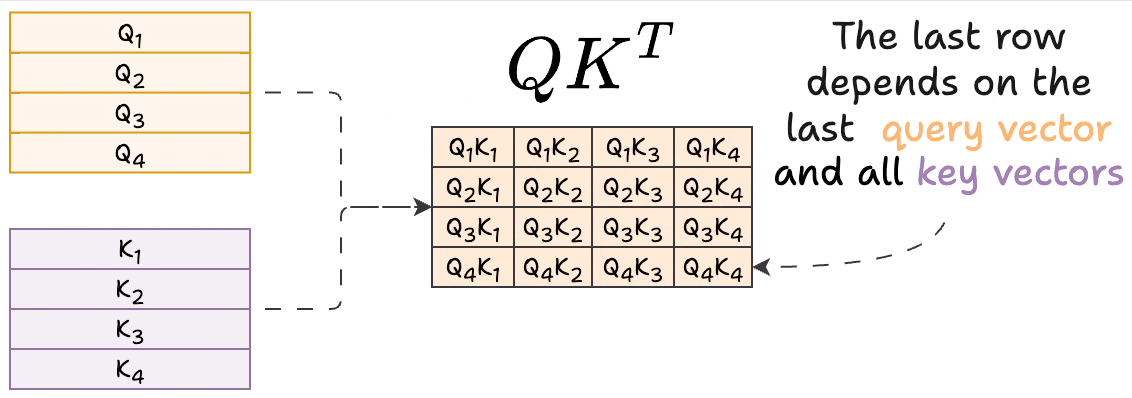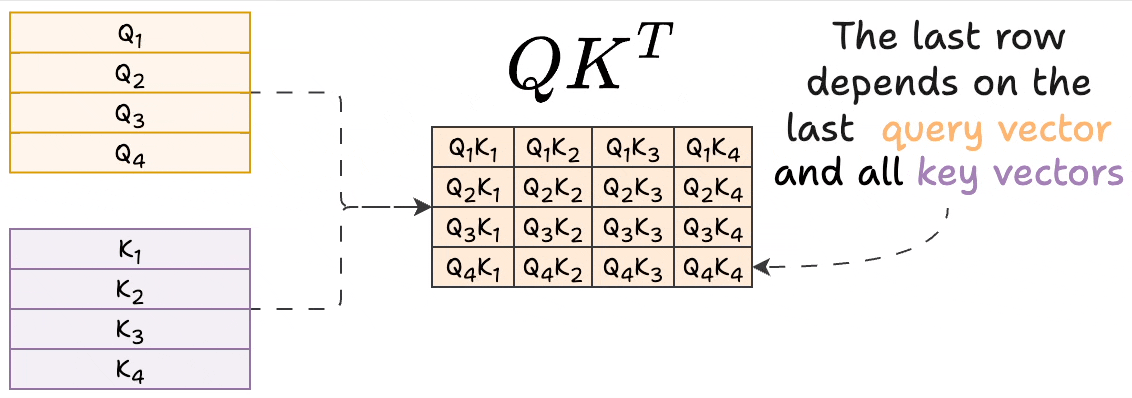
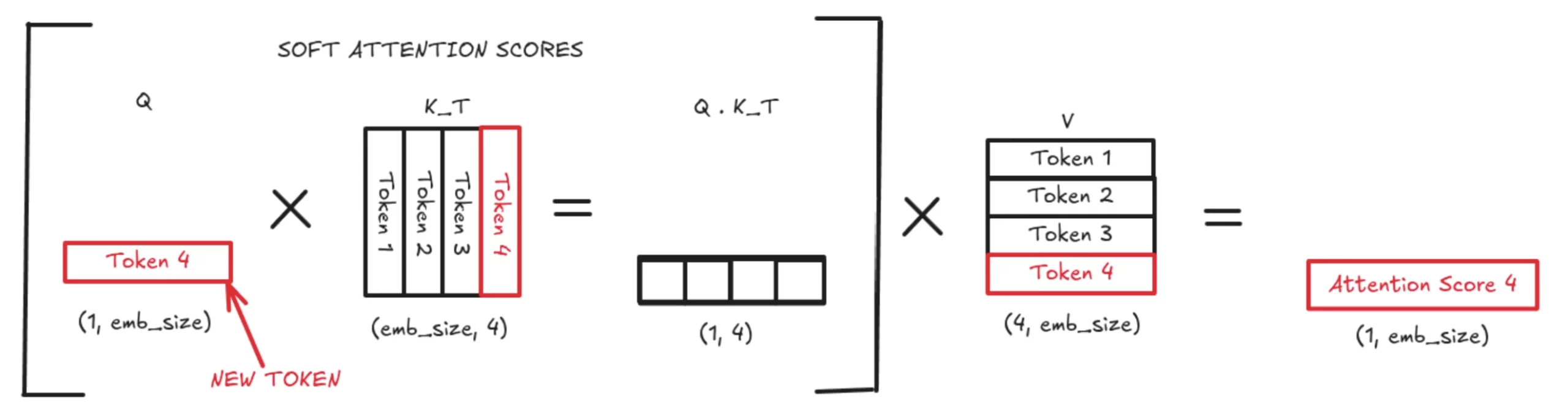
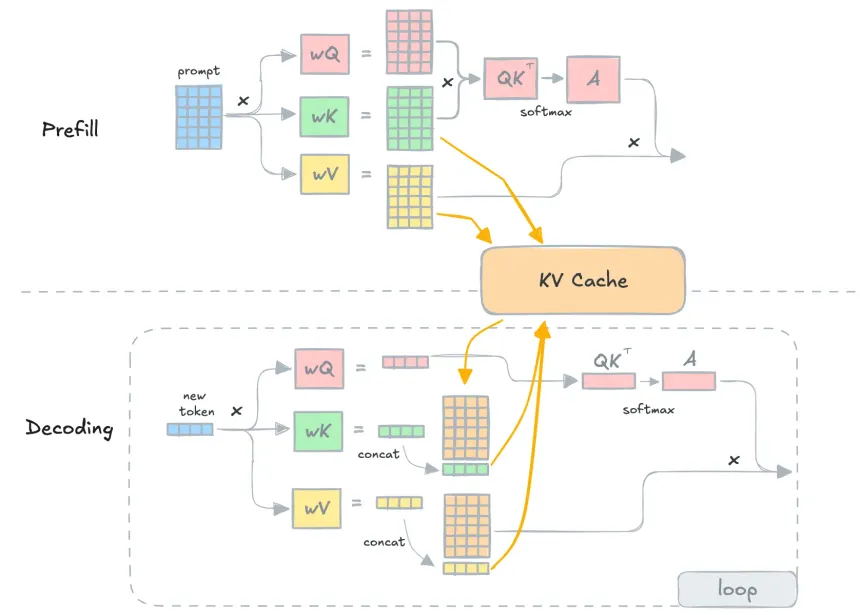
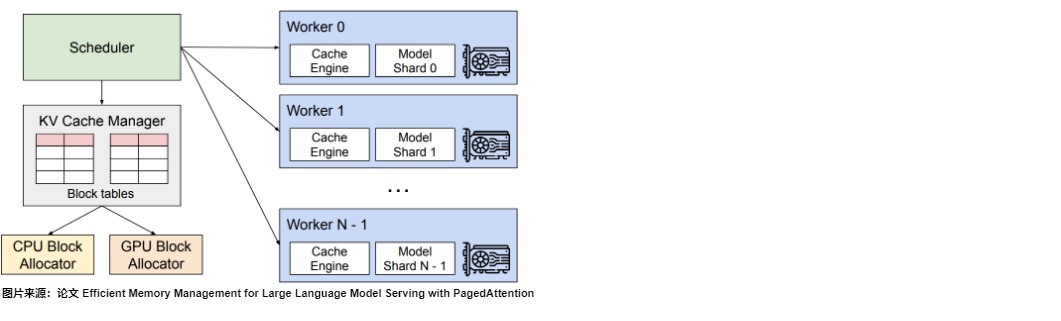
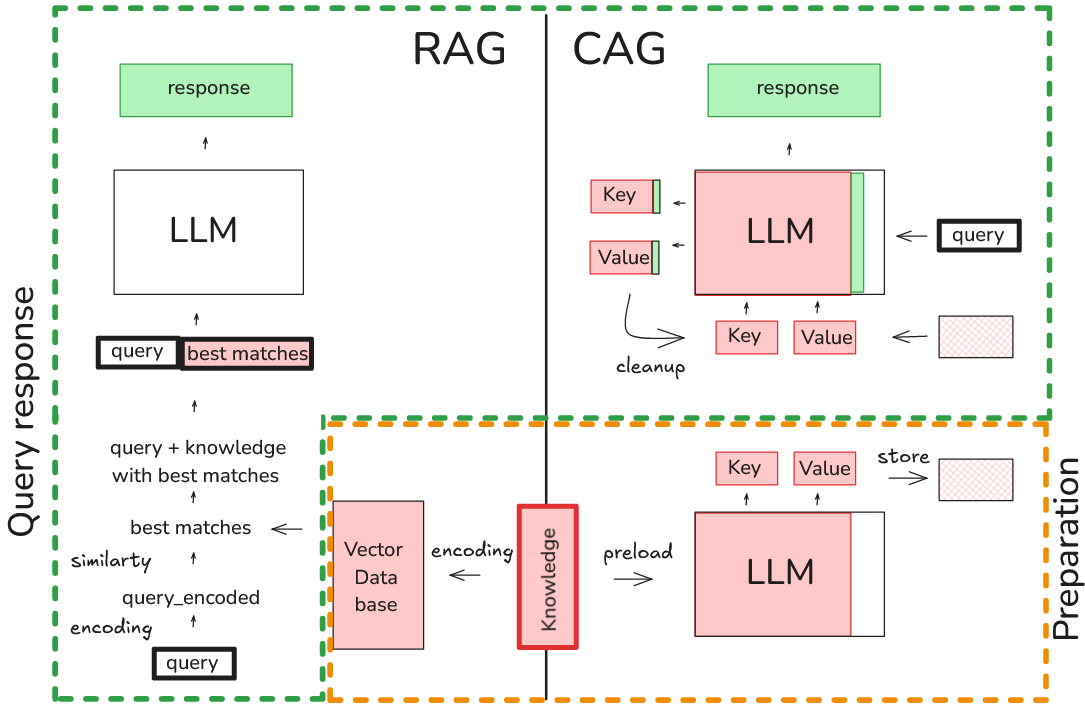
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
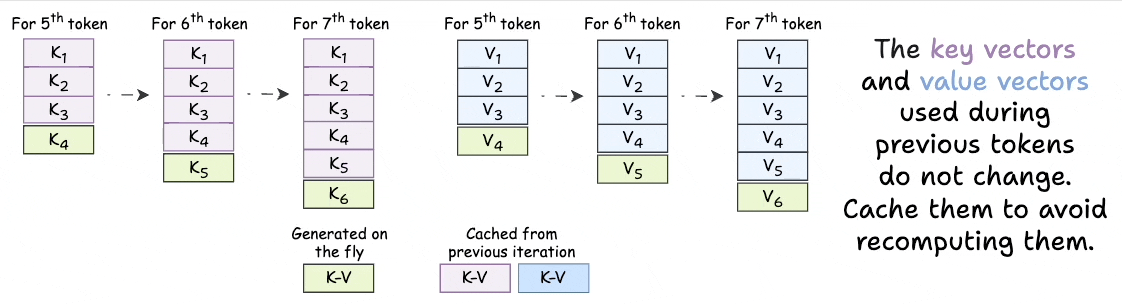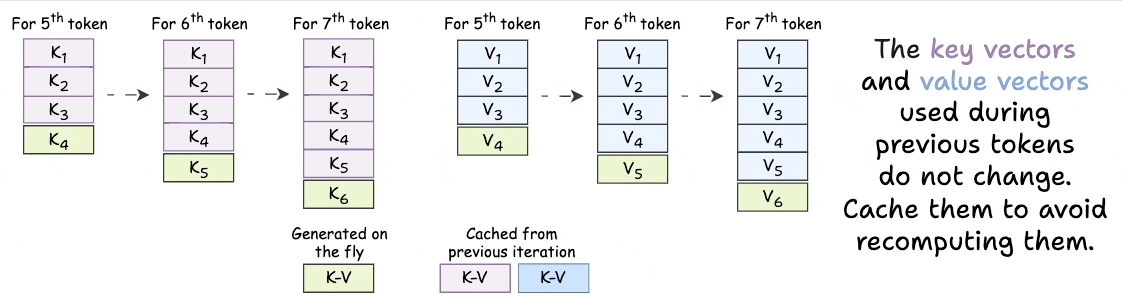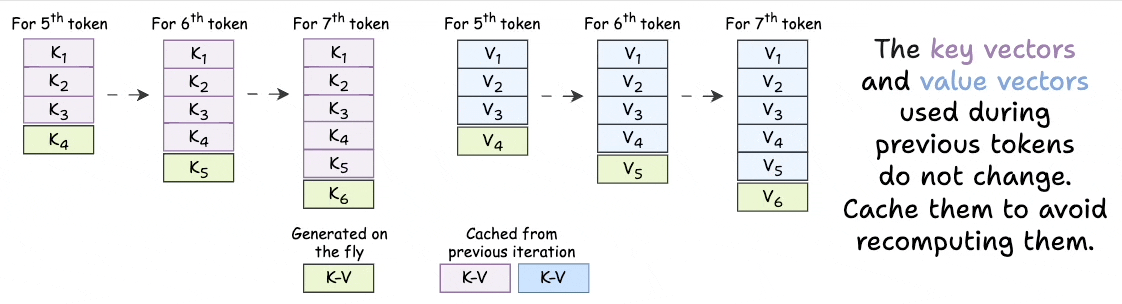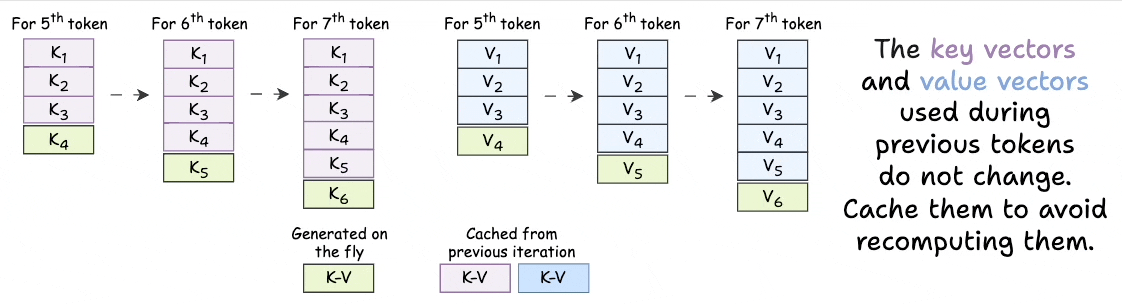
KV Cache Explained with Examples from Real World LLMs
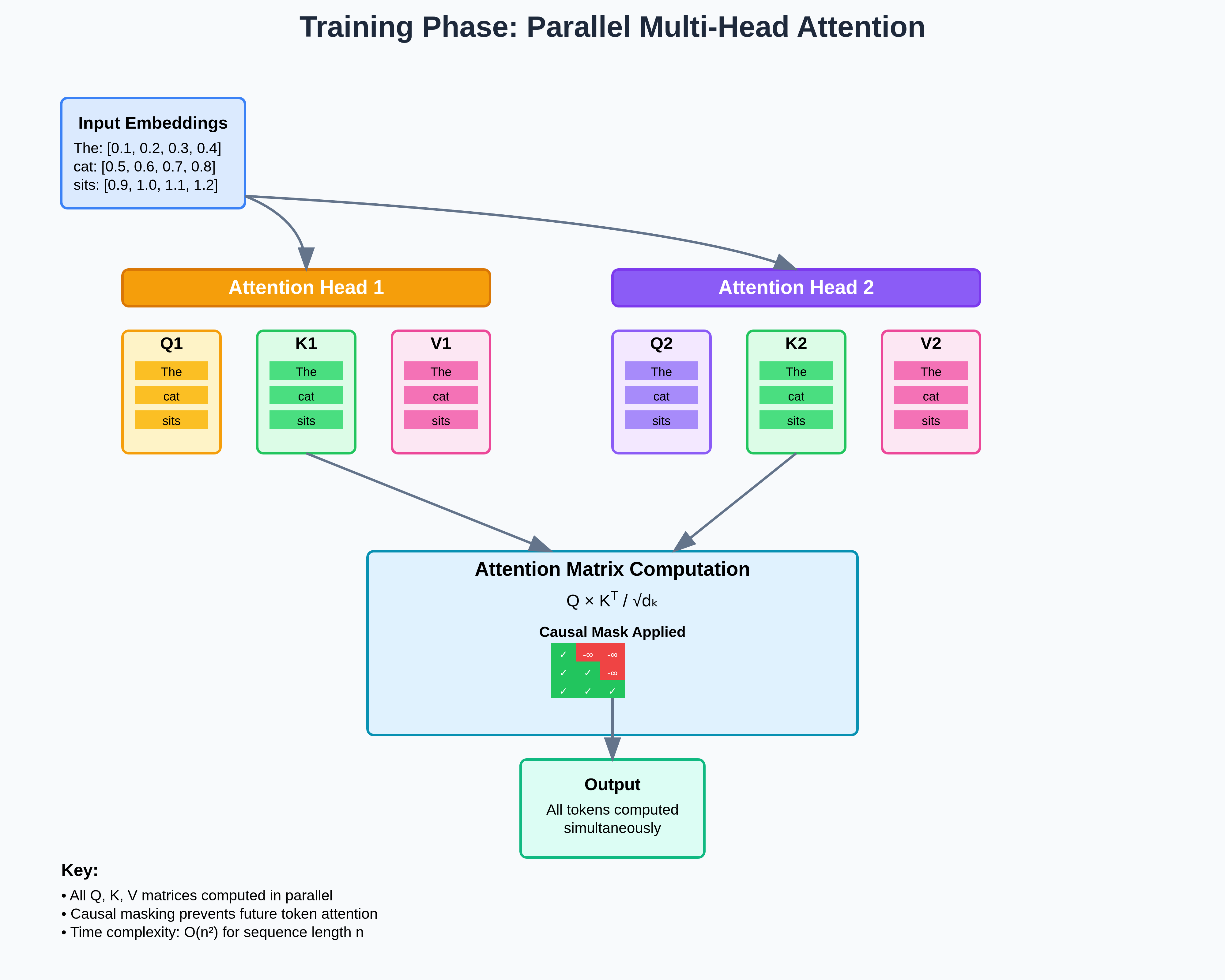
Understanding and Coding the KV Cache in LLMs from Scratch
Global Multi-Level KV Cache - xLLM
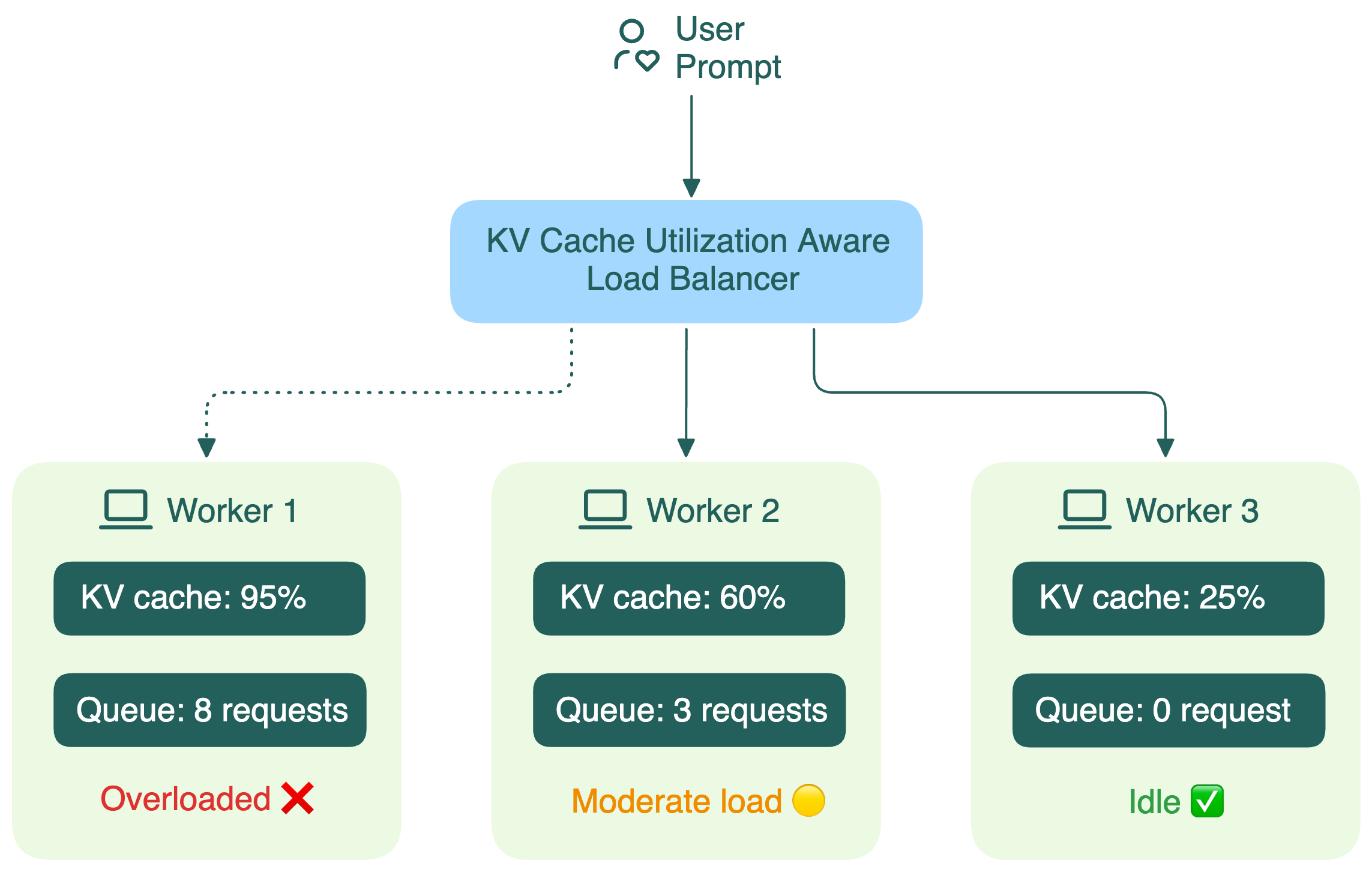
KV cache utilization-aware load balancing | LLM Inference Handbook
Techniques for KV Cache Optimization in Large Language Models
LLM Jargons Explained: Part 4 - KV Cache - YouTube
Welcome to my blog! - Understanding KV Cache
How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA ...
KV Cache in Transformer Models - Data Magic AI Blog
KV Cache 详解:新手也能理解的 LLM 推理加速技巧-CSDN博客
Core Strategies for Optimizing the KV Cache | by M | Foundation Models ...
How To Use KV Cache Quantization for Longer Generation by LLMs - YouTube
Master KV cache aware routing with llm-d for efficient AI inference ...
整合 Speculative Decoding 和 KV Cache 之實作筆記 - Clay-Technology World
How KV Cache Works & Why It Eats Memory | by M | Foundation Models Deep ...
Caching Strategies for LLM Systems (Part 2): KV Cache and the ...
5x Faster Time to First Token with NVIDIA TensorRT-LLM KV Cache Early ...
KV Cache Architecture | liguodongiot/nano-vllm | DeepWiki
Distributed KV Cache — AIBrix
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
Introducing New KV Cache Reuse Optimizations in NVIDIA TensorRT-LLM ...
KV Cache Quantization Overview
第四十六章:AI的“瞬时记忆”与“高效聚焦”:llama.cpp的KV Cache与Attention机制_llamacpp kv cache ...
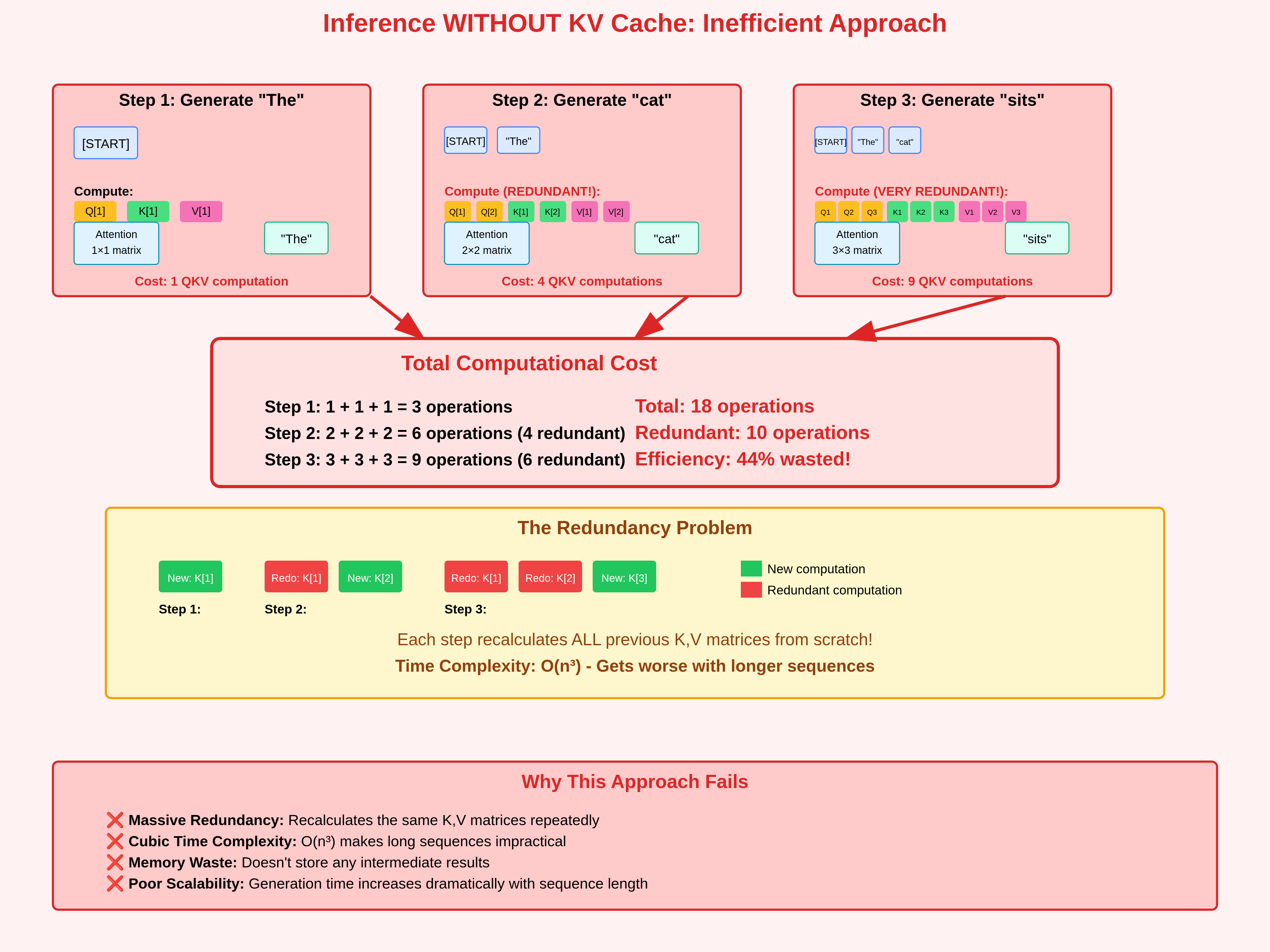
Speeding up the GPT - KV cache | Becoming The Unbeatable
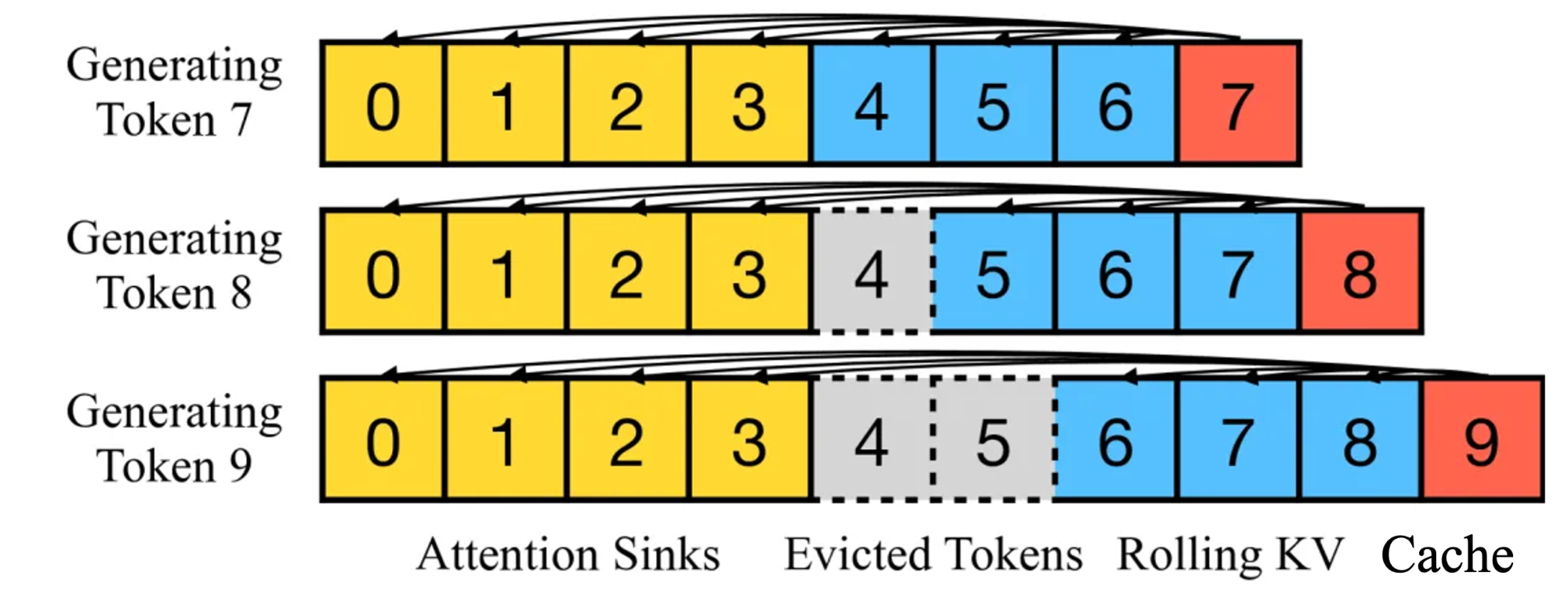
UX - SimLayerKV: An Efficient Solution to KV Cache Challenges in Large ...
KV Cache - 从矩阵运算的角度理解 - 知乎
LLM inference optimization - KV Cache - MartinLwx's Blog
Introduction to KV Cache Transmission — TensorRT LLM
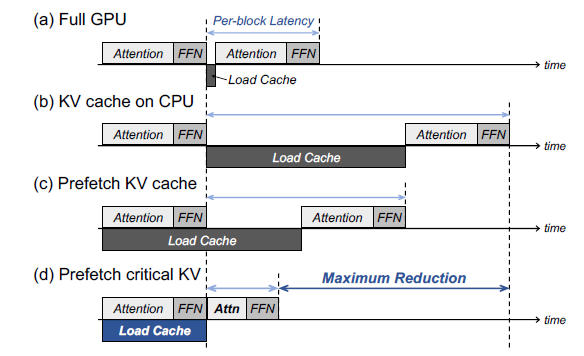
Scaling Multi-Turn LLM Inference with KV Cache Storage Offload and Dell ...
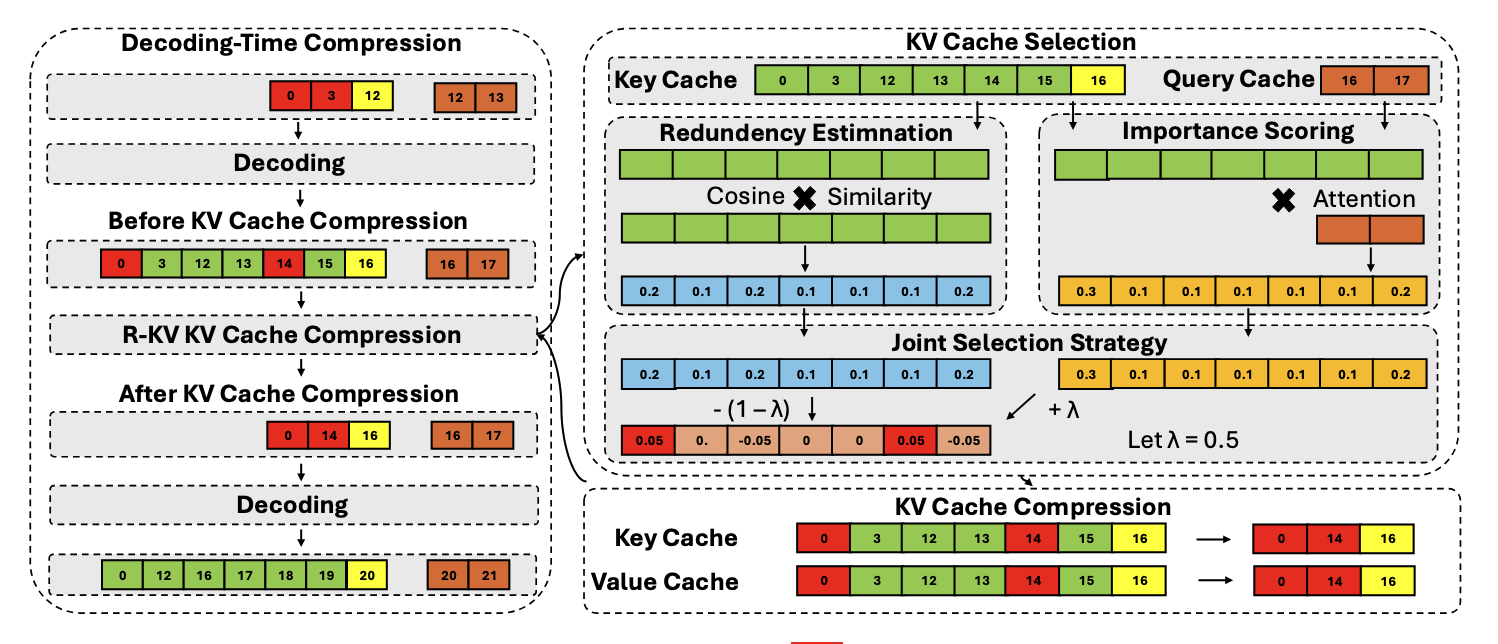
R-KV: Redundancy-aware KV Cache Compression for Reasoning Models
fp8 Weight, Activation, and KV Cache Quantization - LLM Compressor Docs
KV Caches and Time-to-First-Token: Optimizing LLM Performance
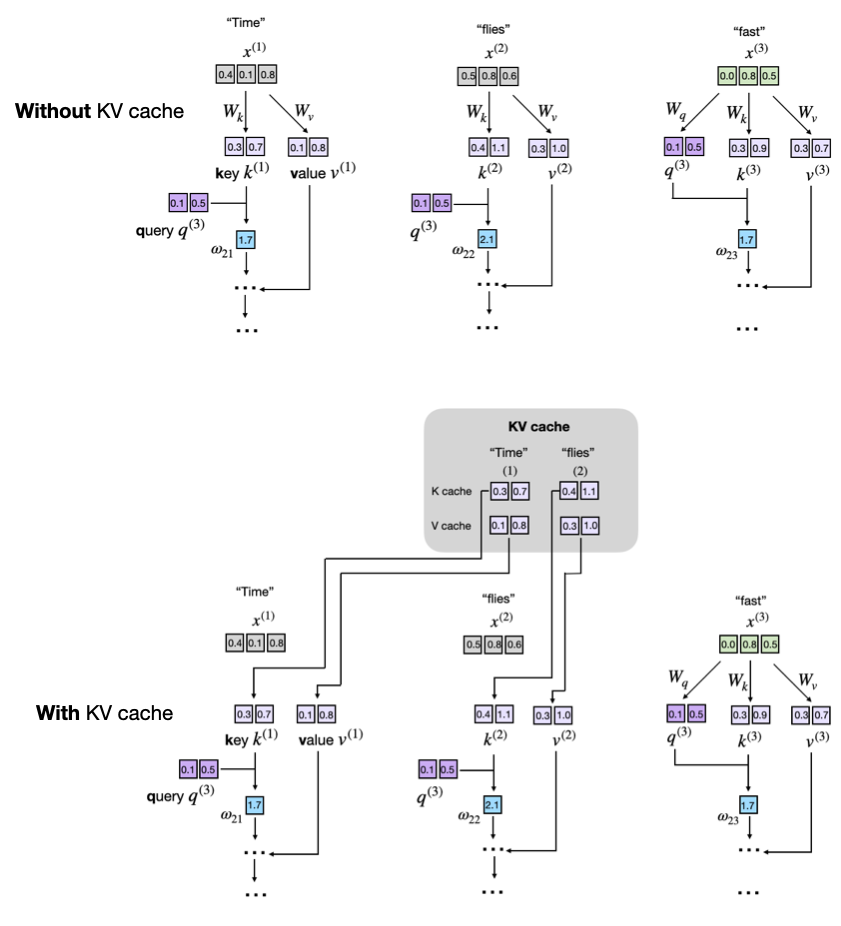
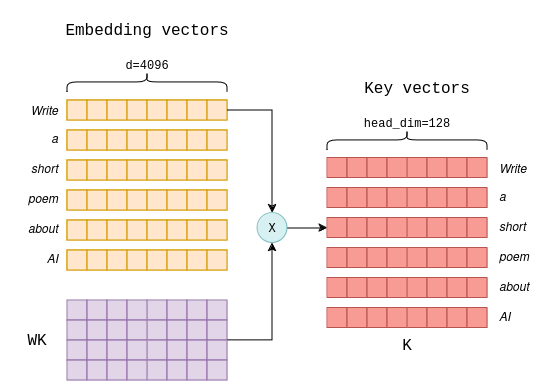
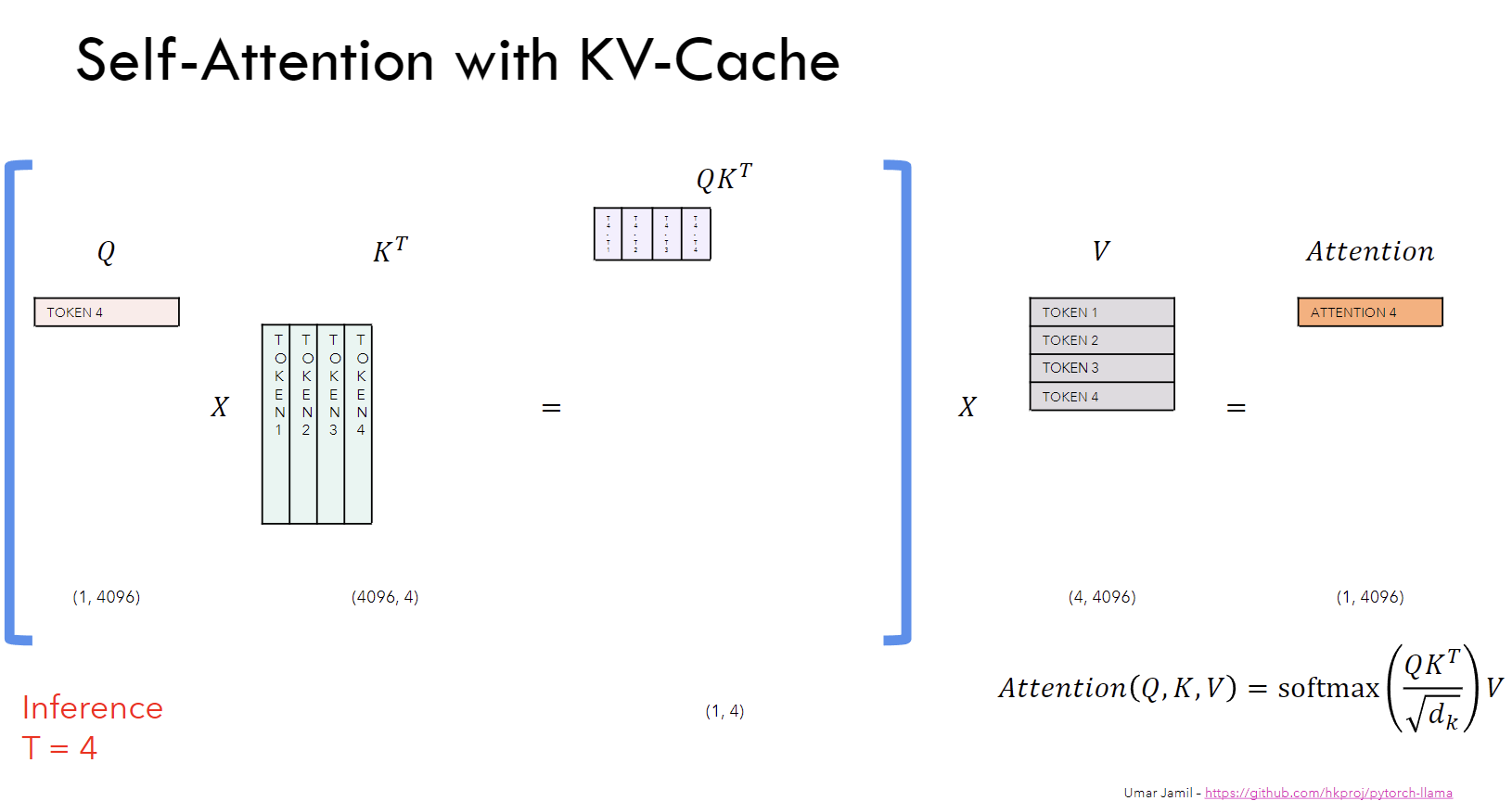
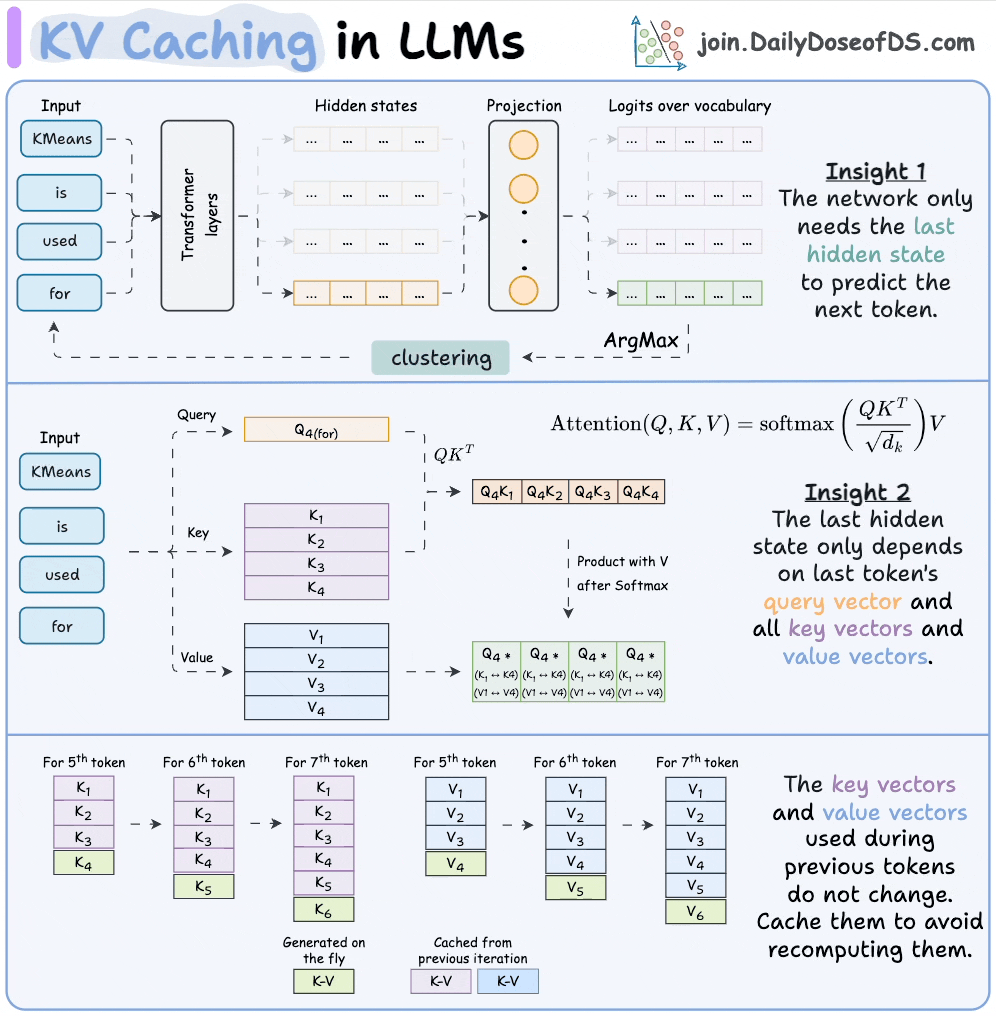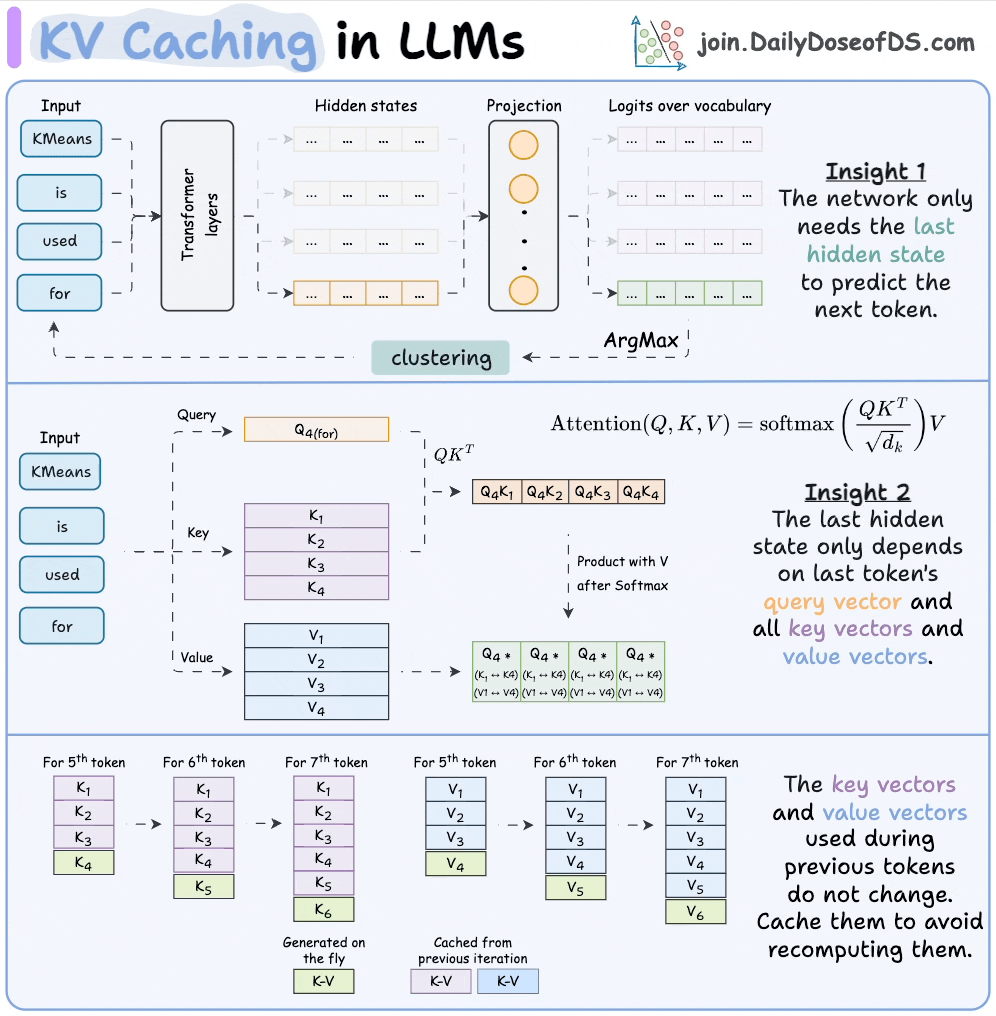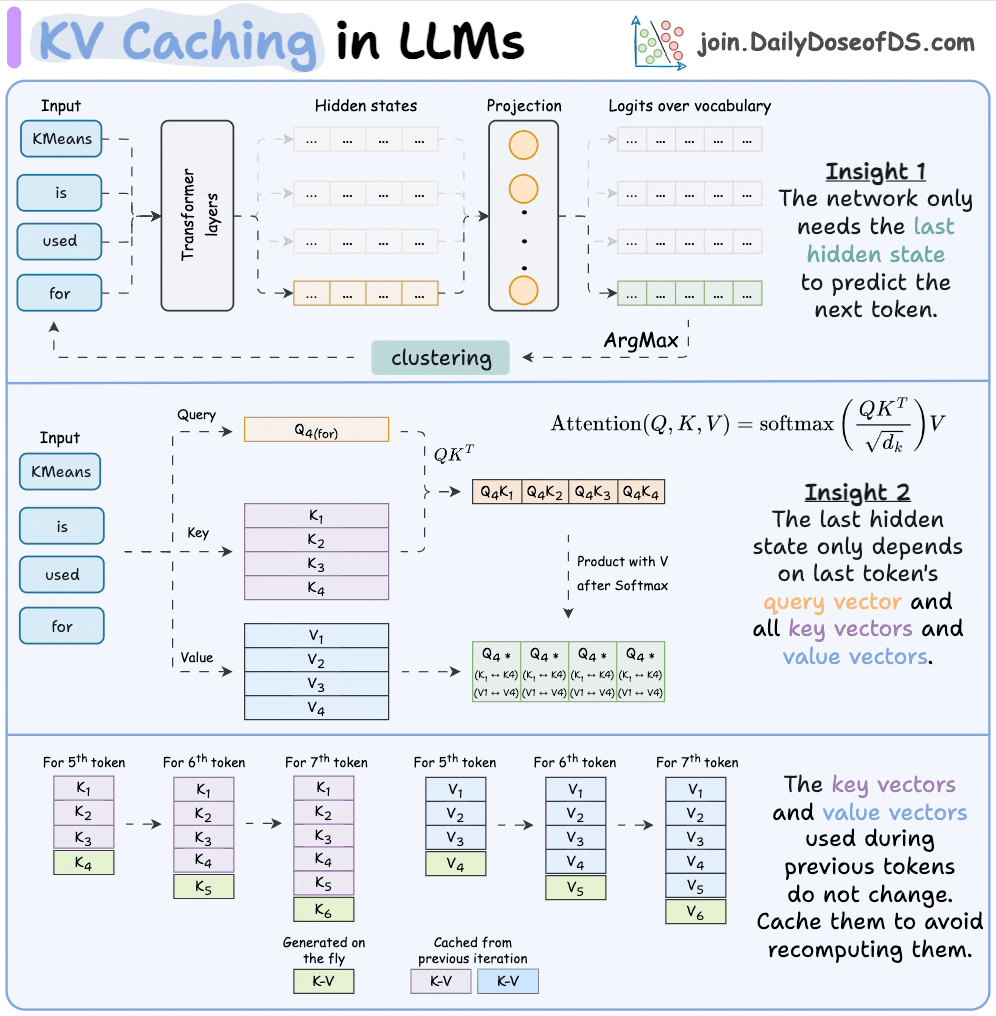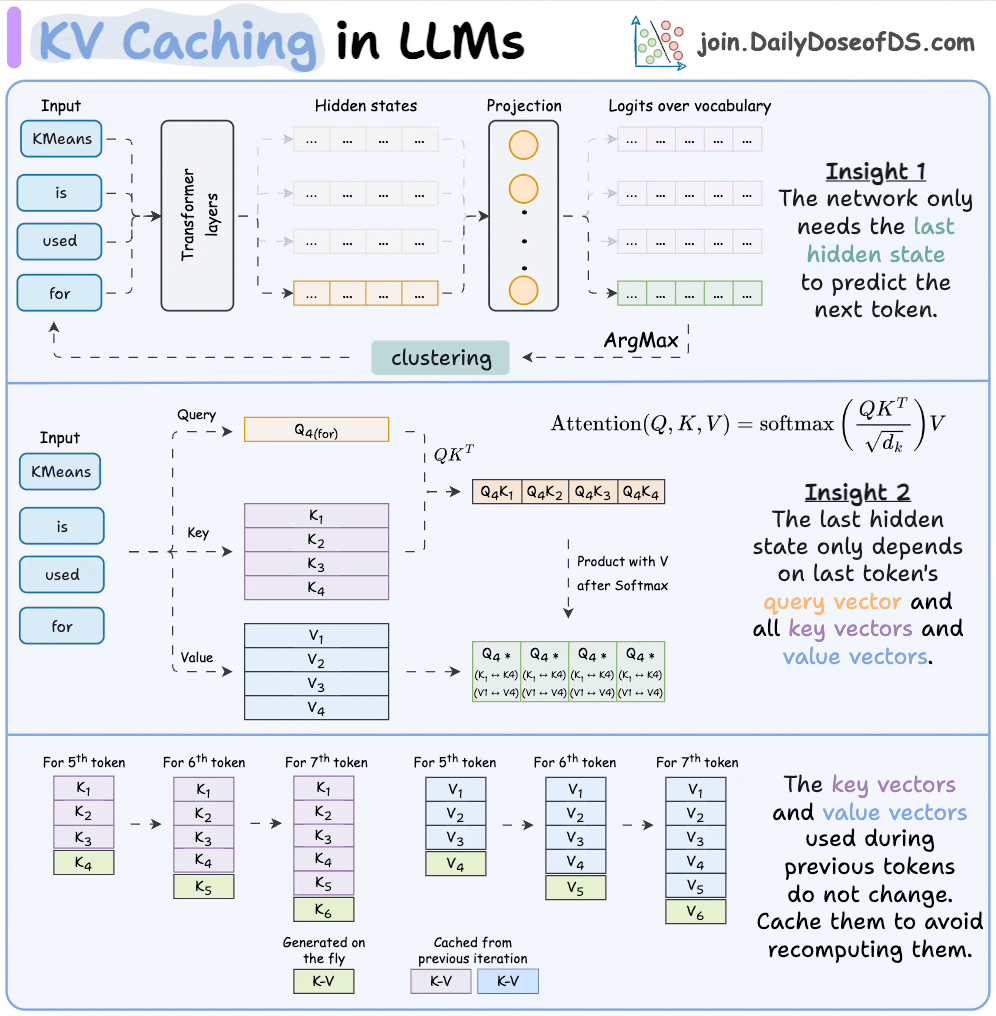
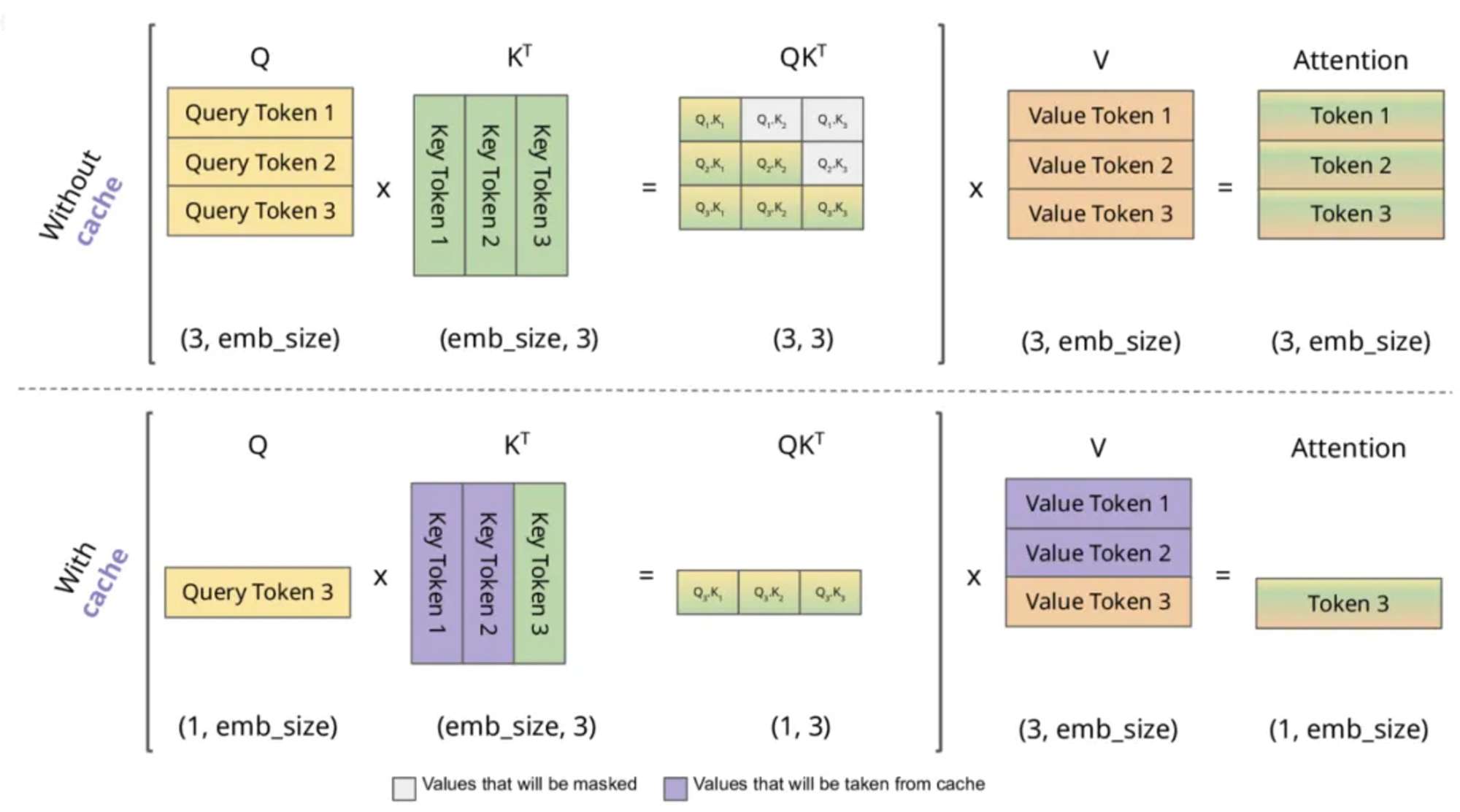
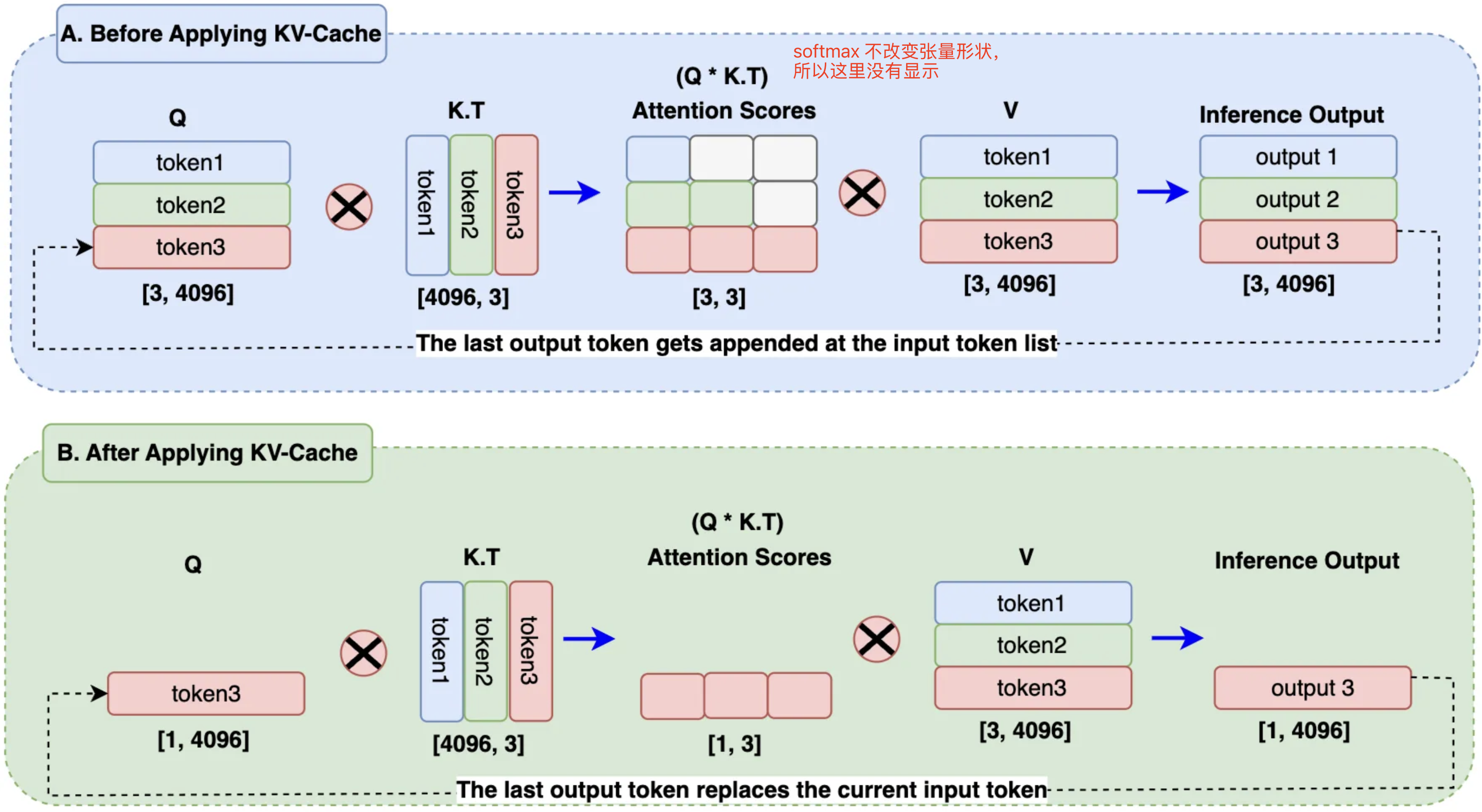
KV Caching in LLMs, explained visually
What is KV Cache?. Standard transformers are powerful but… | by M ...
KV Caching in LLMs, Explained Visually. - by Avi Chawla
KV Caching Illustrated | Kapil Sharma
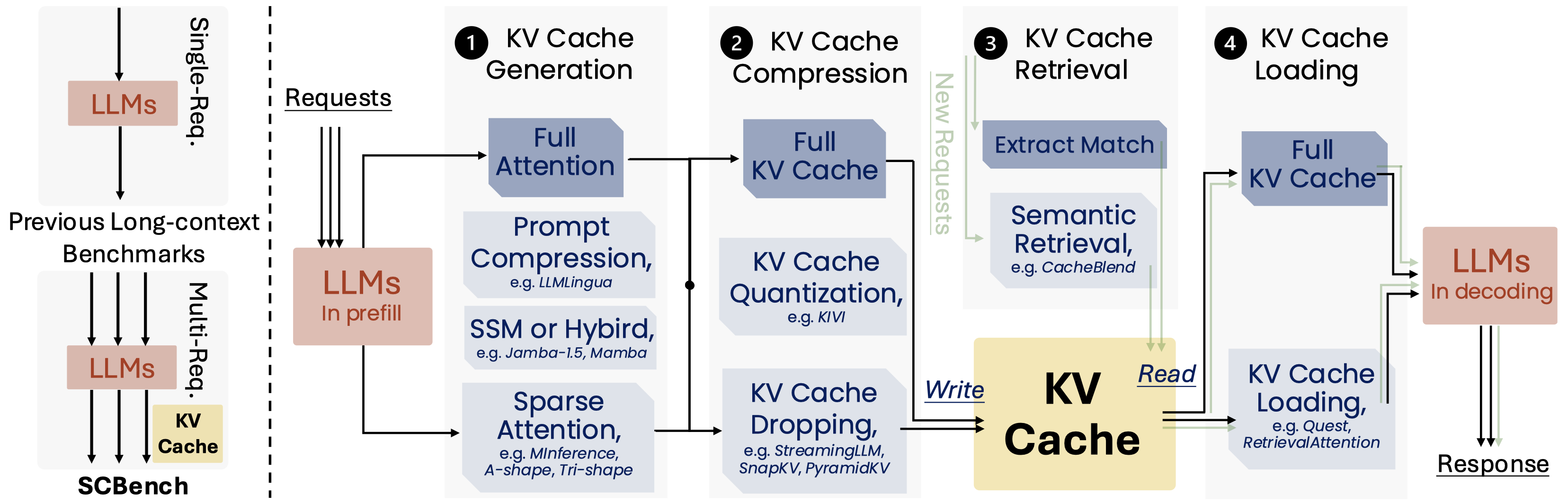
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
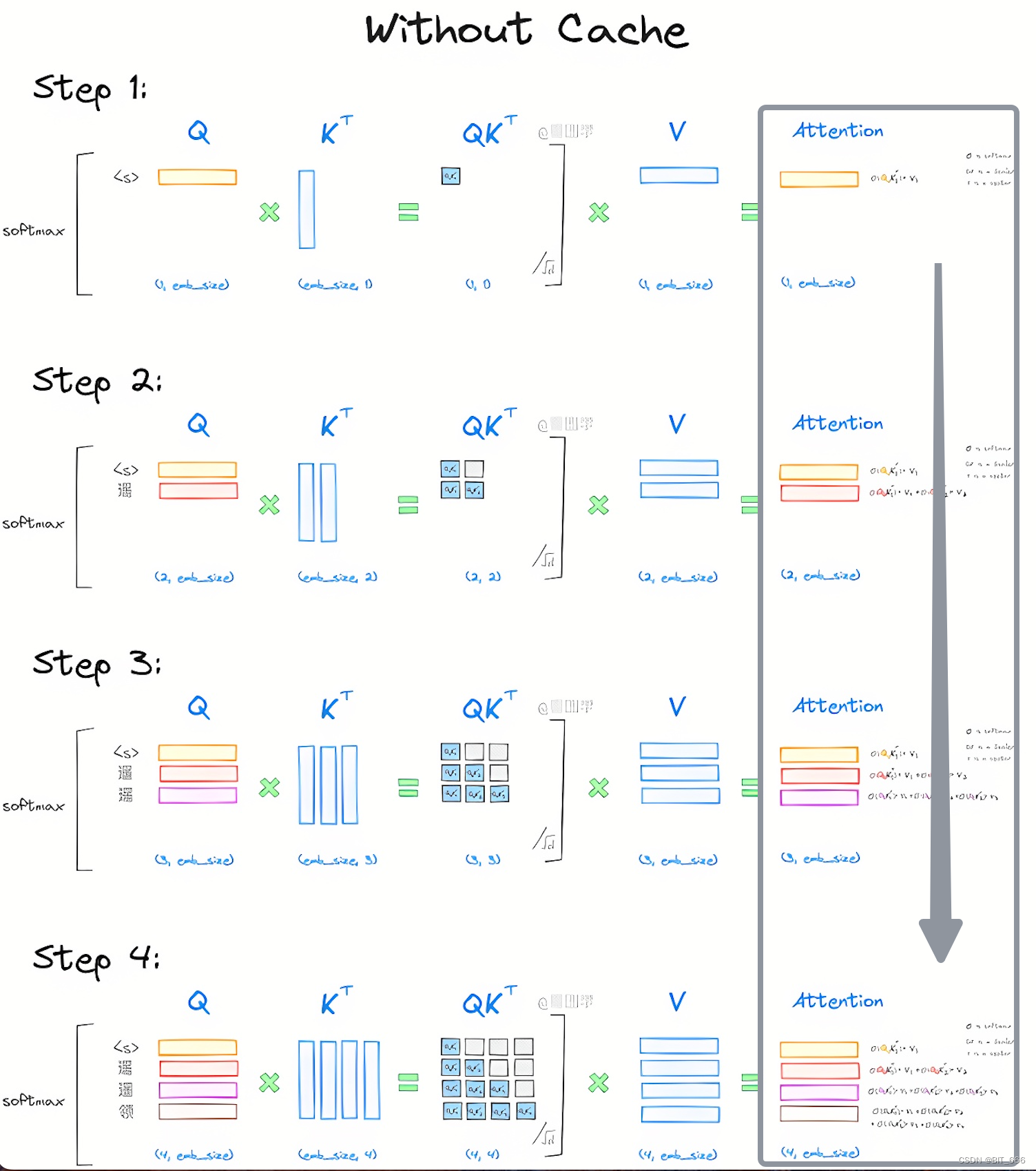
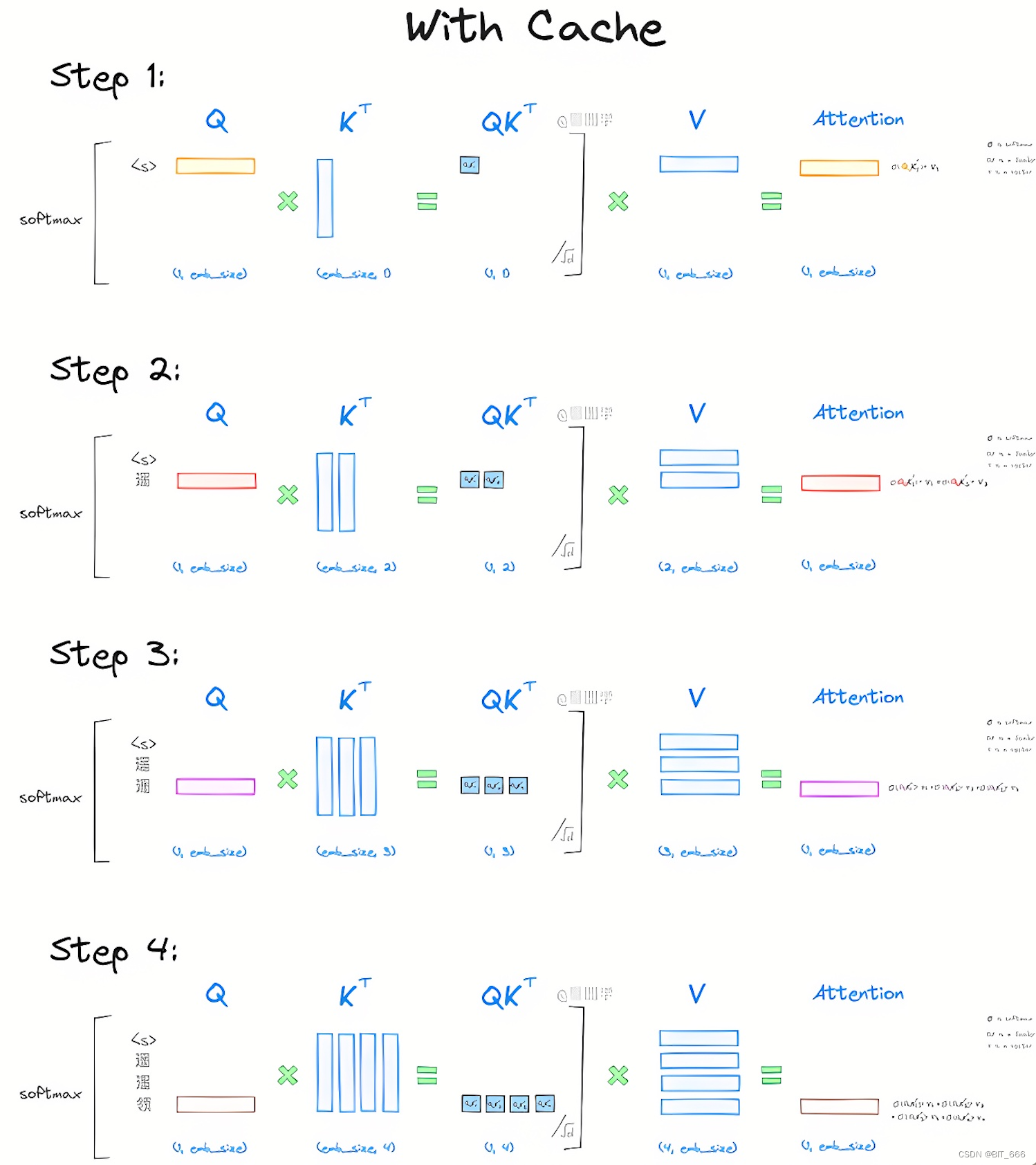
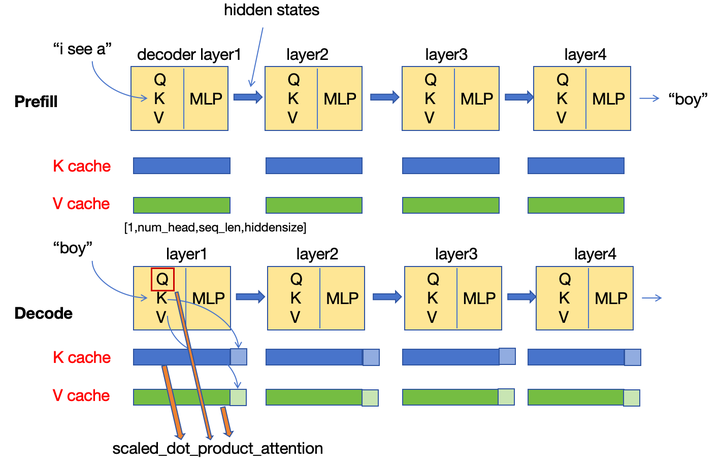
LLM - Generate With KV-Cache 图解与实践 By GPT-2_llm kv cache-CSDN博客
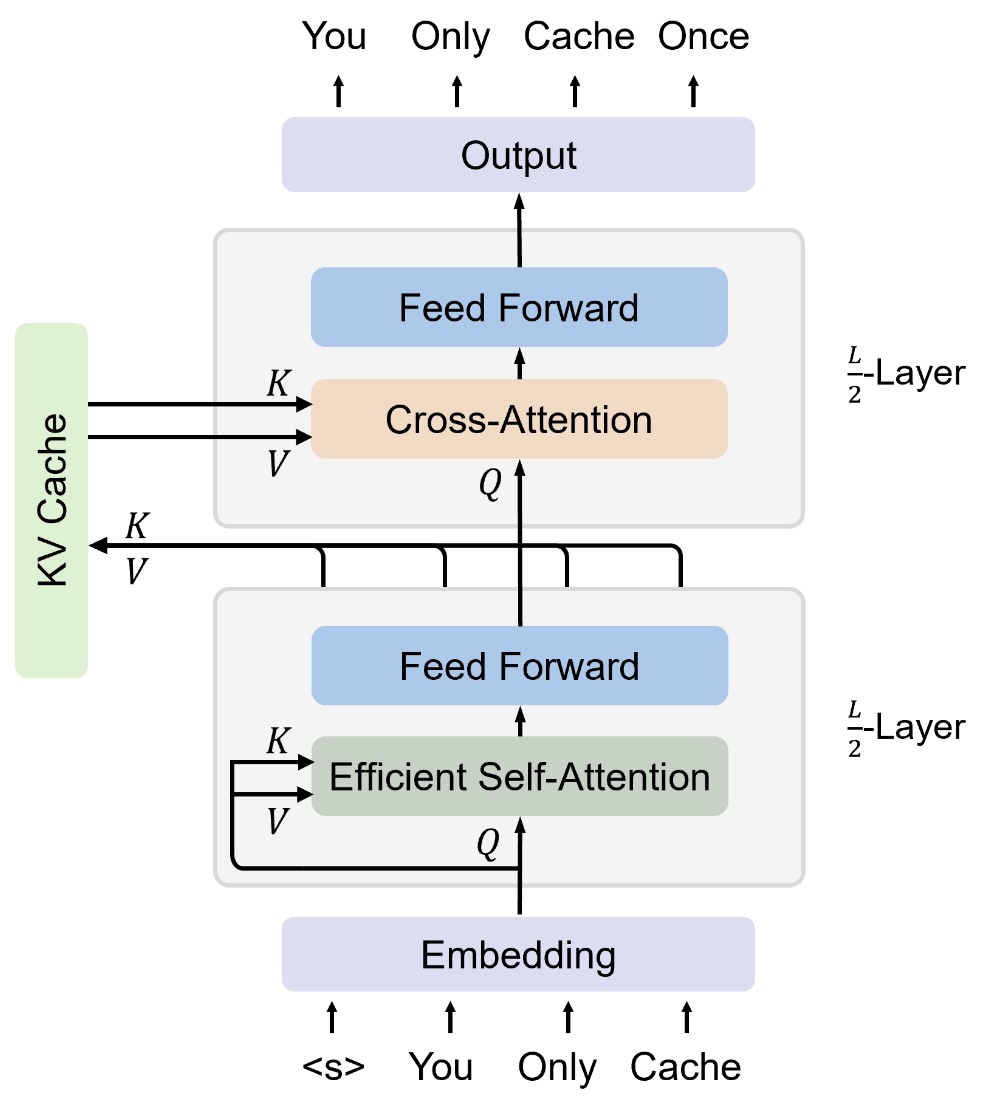
Efficient AI: KV Caching and KV Sharing | Gaurav's Blog
3分钟了解什么是KV Cache - 知乎
KV Cache:图解大模型推理加速方法_kvcache图解-CSDN博客
KV Caching Explained: Optimizing Transformer Inference Efficiency
Entropy-Guided KV Caching for Efficient LLM Inference
KV Cache量化技术详解:深入理解LLM推理性能优化_ollama kv cache-CSDN博客
KV Cache量化技术详解:深入理解LLM推理性能优化 - 知乎
What is the KV cache? | Matt Log
What is the Transformer KV Cache?
Transformers KV Caching Explained | by João Lages | Medium
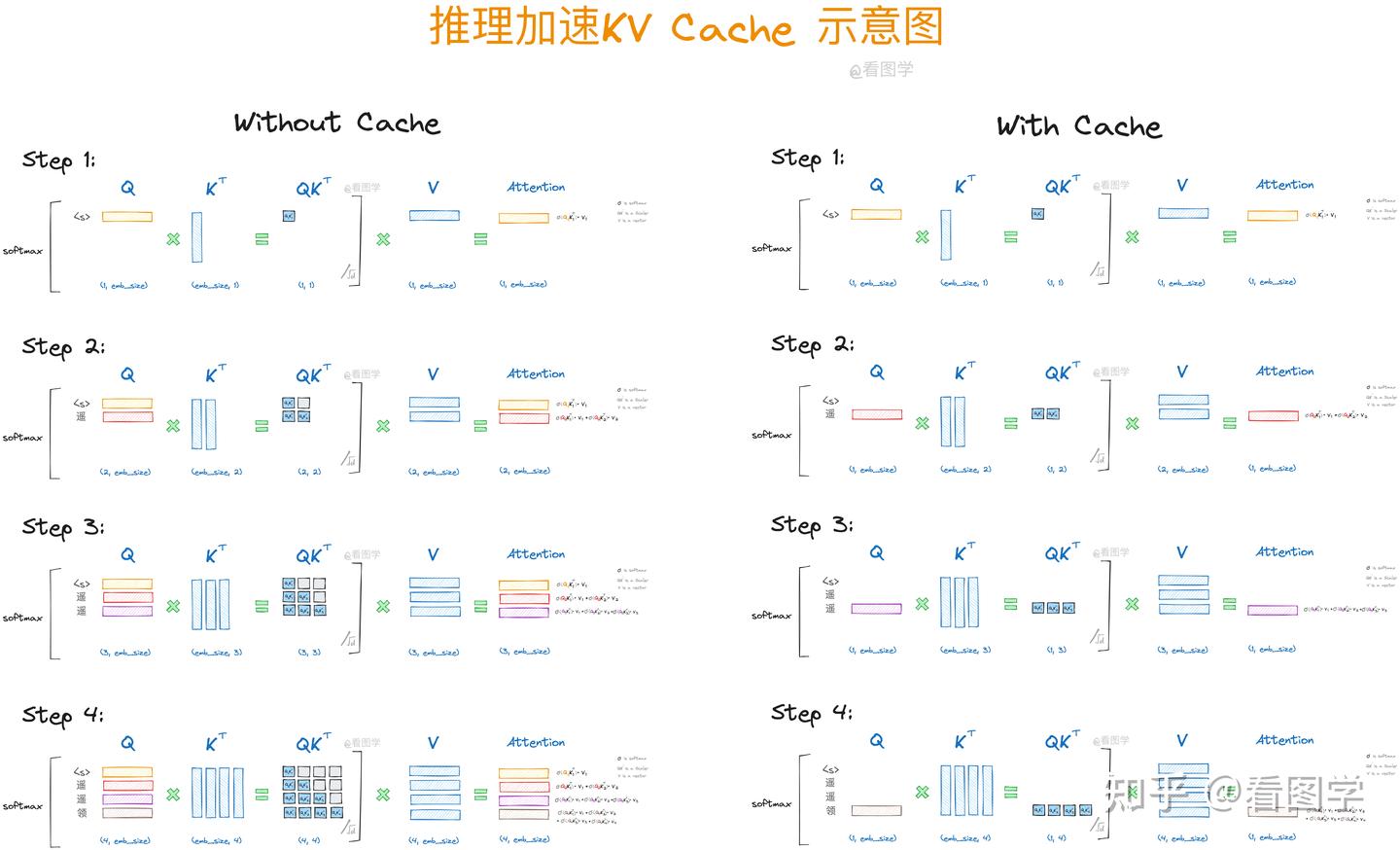
大模型推理加速:看图学KV Cache - 知乎
How KV Caching Makes Modern LLMs Fast?
大模型推理加速:KV Cache Sparsity(稀疏化)方法 - 知乎
KV Cache传输引擎全面解析:从原理到性能对比 - 知乎
一种全新的“可训练 KV Cache”范式-Cartridges - 知乎
KV caching explained-CSDN博客
How KV Caching Works in Large Language Models | MatterAI Blog
KV Cache: The Hidden Optimization Behind Real-Time AI Responses
Understanding KV Caching: The Key To Efficient LLM Inference - ML Digest
AI Interview Series #4: Explain KV Caching - MarkTechPost
Transformers KV Caching Explained-CSDN博客
探秘Transformer系列之(24)--- KV Cache优化 - 罗西的思考 - 博客园
GPU memory requirements for serving Large Language Models | UnfoldAI
Mastering LLM Techniques: Inference Optimization – GIXtools
【手撕LLM-KVCache】显存刺客的前世今生--文末含代码 - 知乎
Attention Mechanisms in Transformers: Comparing MHA, MQA, and GQA | Yue ...
Meet 'kvcached': A Machine Learning Library to Enable Virtualized ...
大模型推理优化实践:KV cache复用与投机采样 - 知乎
Mastering Long Contexts in LLMs with KVPress
Figure 1 from SqueezeAttention: 2D Management of KV-Cache in LLM ...
How To Reduce LLM Decoding Time With KV-Caching!
KV-Cache Wins You Can See: From Prefix Caching in vLLM to Distributed ...
大模型推理优化技术-KV Cache_大模型kv cache-CSDN博客
How does prompt caching work? · Sara Zan
kvcache原理、参数量、代码详解_kv cache-CSDN博客
KV-cache
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
My journey understanding: KV-Cache. Clarifying and correcting relevant ...
vLLM 内参深度剖析 - d.run 让算力更自由
LLM - Generate With KV-Cache 图解与实践 By GPT-2_gpt2 kv缓存的使用和实现-CSDN博客
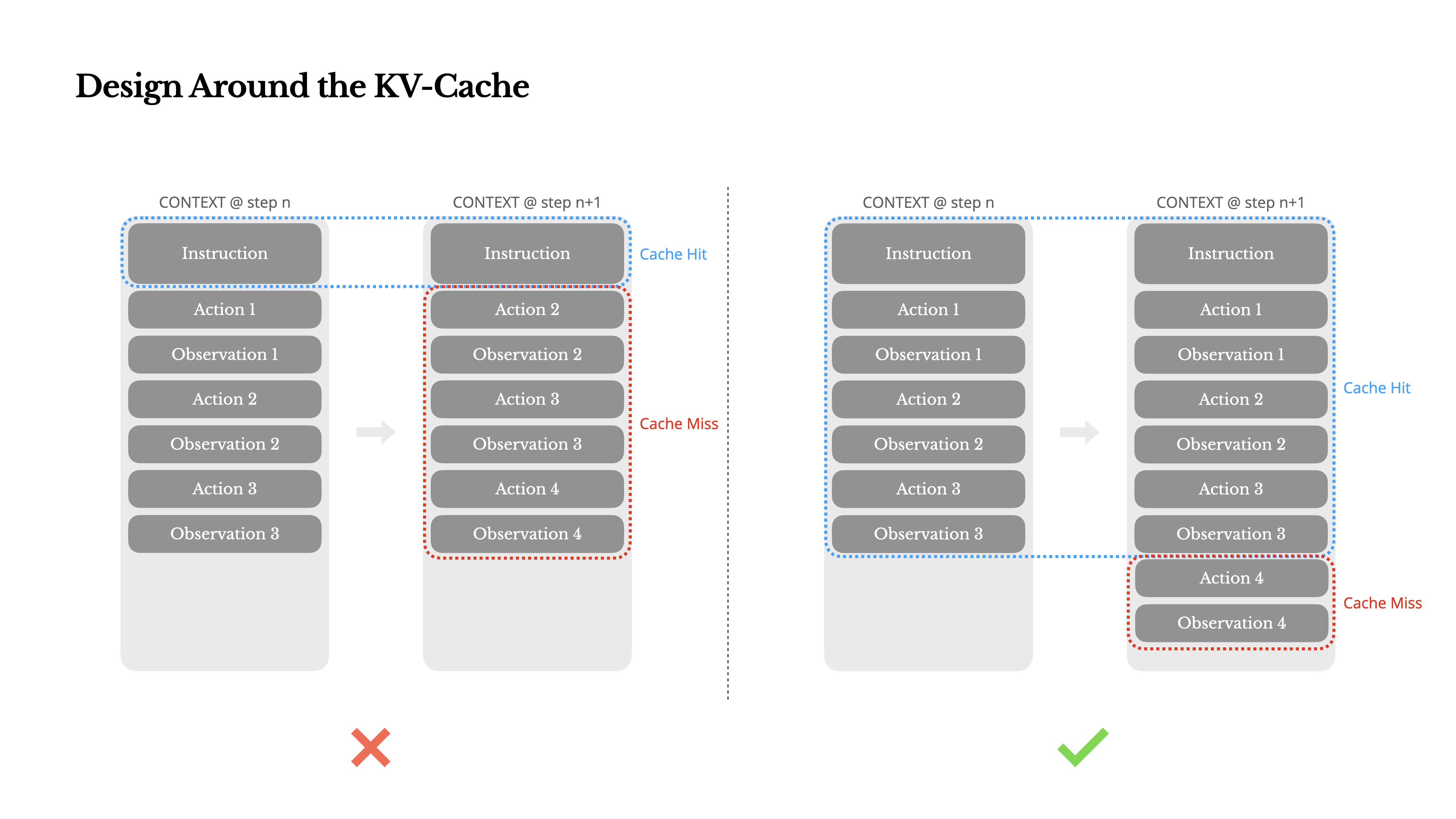
Context Engineering for AI Agents: Lessons from Building Manus | AI ...
大模型百倍推理加速之KV cache篇 - 知乎
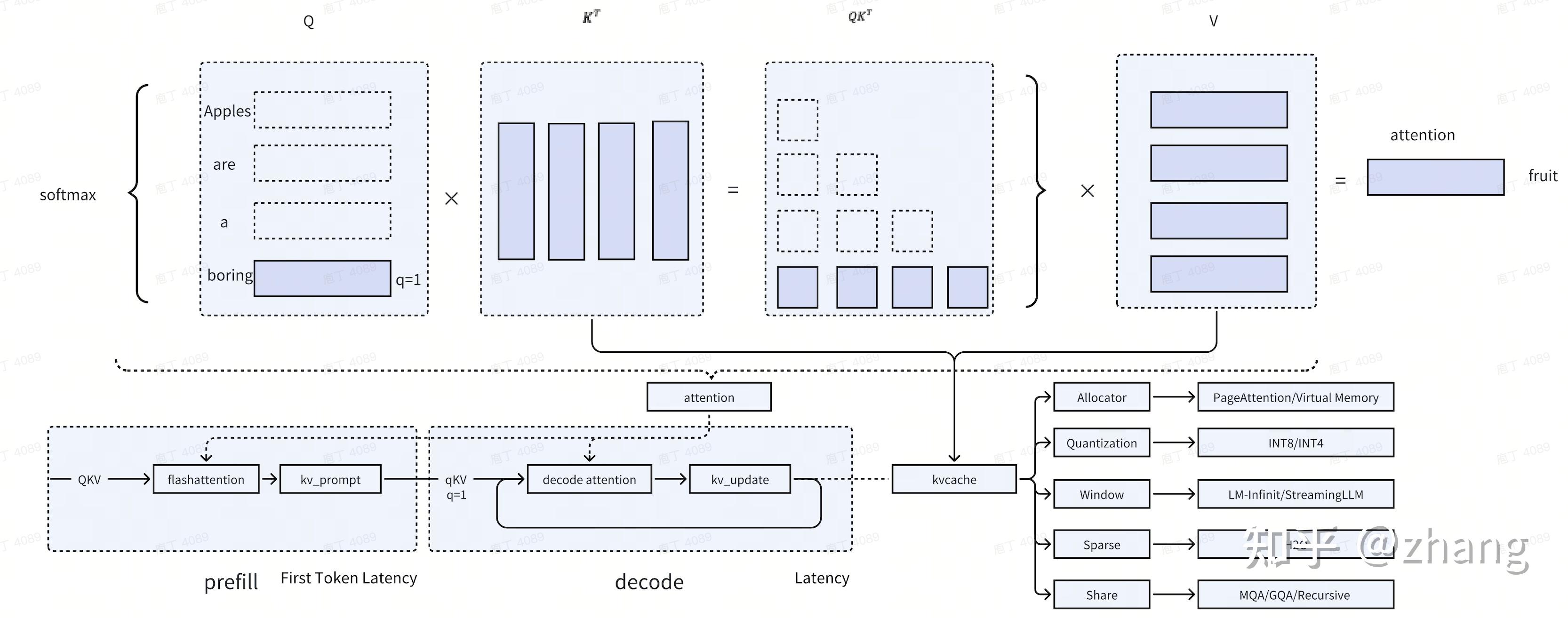
kv-cache 原理及优化概述 - Zhang
使用KV Cache作为在线临时数据库 | RavelloH's Blog
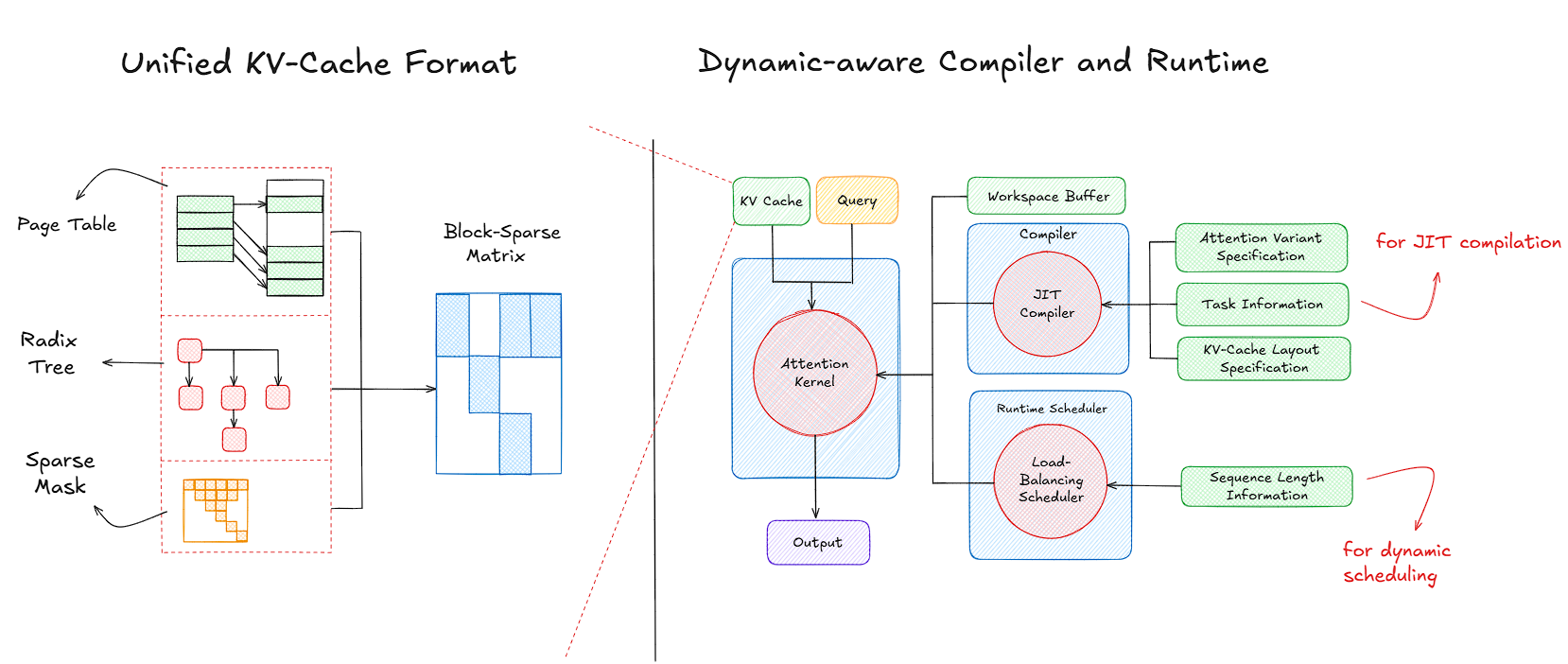
Dissecting FlashInfer - A Systems Perspective on High-Performance LLM ...
大模型推理时的KV cache介绍和实践 - 知乎
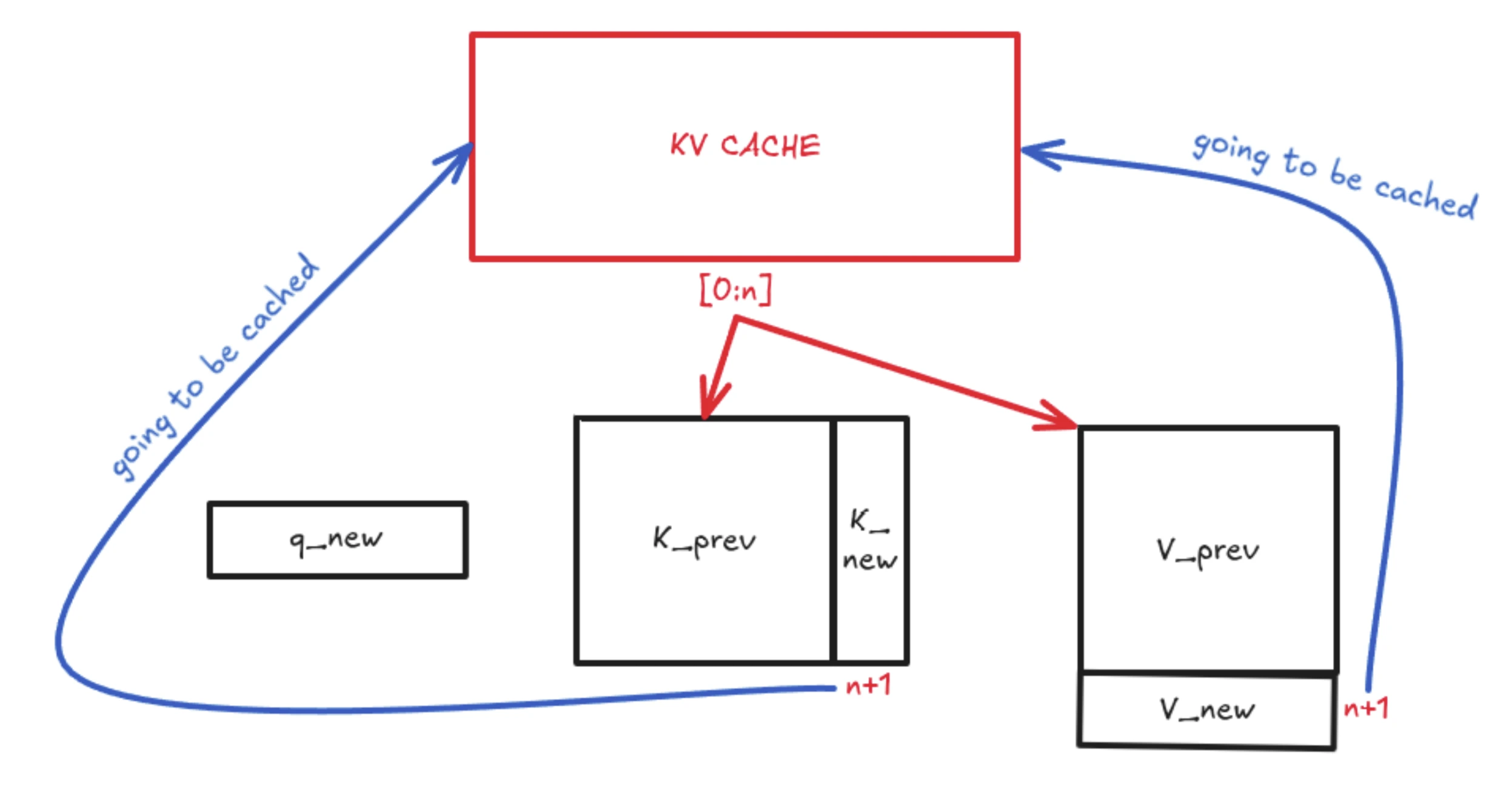
可视化KV Cache的原理(代码实现的角度) - 知乎
玩转大语言模型:深入理解 KV-Cache - 大模型推理的核心加速技术 | Wilson Wu
20. Inference Acceleration (WIP) — LLM Foundations